BF-Tree: Approximate Tree Indexing on VLDB 2014.
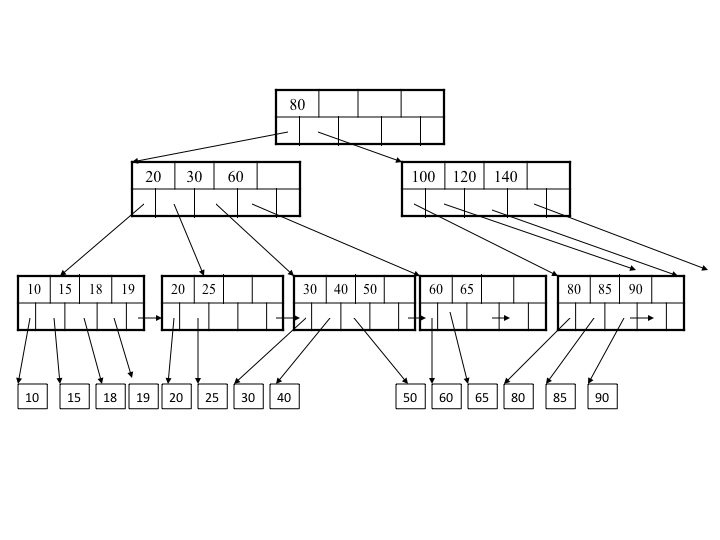
A B tree is a self-balancing binary tree. To locate an item on B tree stored on HDD, huge number of small random read need to be performed. A B+ tree is a specialized version of a B tree with a variable but often large number of children per node. Thus, items on B+ tree can be located with fewer number of random read. Tree structures, especially B+ Trees are widely used because they are optimized for the common storage technology – HDD – and they offer efficient indexing and accessing for both sorted and unsorted data (e.g., in heap files). Most modern, popular databases use B+ trees for storage (Oracle, Postgresql, Mysql, Microsoft SQL Server, …). A B+ tree looks like:
Indexing on SSDs also adopt B+ trees and focus on addressing the slow writes on flash and the limited device lifetime. However, random read in SSDs are only 1/2 to 1/3 worse than sequential read. This paper propose to employs probabilistic data structures (Bloom filters) to trade accuracy for size and produce smaller, yet powerful, tree indexes – BF-Trees.

Each leaf node corresponds to a page range (min_pid – max_pid) and to a key range (min_key – max_key), and it consists of a number, S, of BFs , each of which stores the key membership for each page of the range (or a group of consecutive pages).
Compared to the B+ tree, which consists of large leafs, BF-Trees is a more compact data structure.
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set. So, why bloom filter is good for data index?
This is because the data sets have is implicit clustering. The relevant data are trend to clustered on the time dimension, thus can be co-located on the storage. For a given segment, only a small number of relevant data need to be indexed:

This gives the evidence that Correlated Data can be co-located.