Scaling Concurrent Log-Structured Data Stores on Eurosys 2015 by Yahoo!.
This is another “tree” related paper. Different to BF-Tree, which use bloom filter to reduce the size of the tree, this paper talks about an algorithm, called cLSM, for scalable concurrency in Log-Structured Merge Data
Stores (LSM-DSs), which exploits multiprocessor-friendly data structures and non-blocking synchronization.
The main concepts of LSM-DSs is “absorbing large batches of writes in a RAM data structure that is merged into a (substantially larger) persistent data store upon spillover”. The major bottleneck of low bandwidth in persistent storage can be hidden by LSM-DSs. This paper focus on improving the scalability of state of the art key-value stores on multicore servers.
There are two types horizontal scalability: horizontal scalability and vertical scalability. The horizontal scalability use partitioning to stretch the service across multiple servers. However, synchronization between servers and partition managements can become the bottleneck. The vertical scalability increase the serving capacity of individual partition. LSM is the leading approach to effectively eliminates the disk bottleneck for write intensive applications. Once this is achieved, the rate of in-memory operations becomes paramount.
The main idea of cLSM is:
eliminating blocking during normal operation. It never explicitly blocks get operations, and only blocks puts for short periods of time before and after batch I/Os.
we use a shared-exclusive lock (sometimes called readers-writer lock [20]), in order to synchronize between put operations and the global pointers’ update.
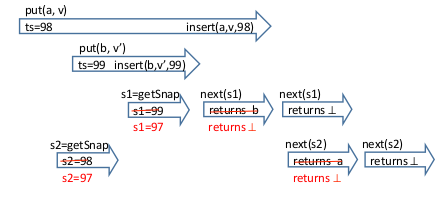
To enable no-block snapshot, key-value pair are turned into key-timestamp-value triples by adding internal timestamps. The timestamps is non-blocking implementations of counters.
In the above figure, since both 98 and 99 are active at the time s1 and s2 are invoked, the snapshot operation choose 97 as their snapshot time.
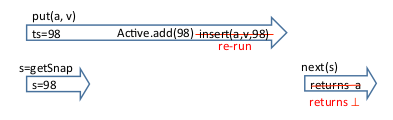
The put operation cannot use the value 98 since a snapshot operation already assumes there are no active put operations before timestamp 99.
The idea is to use optimistic concurrency control – having read v as the latest value of key k, our attempt to insert f (v) fails (and restarts) in case a new value has been inserted for k after v. This situation is called a conflict, and it means that some concurrent operation has interfered between our read step.
cLSM is implemented based on LevelDB.
Google’s LevelDB is the state-of-the-art implementation of a single machine LSM that serves as the backbone in many of such key-value stores. It applies coarse-grained synchronization that forces all puts to be executed sequentially, and a single threaded merge process. These two design choices significantly reduce the system throughput in multicore environment. This effect is mitigated by HyperLevelDB, the data storage engine that powers HyperDex. It improves on LevelDB in two key ways: (1) by using fine-grained locking to increase concurrency, and (2) by using a different merging strategy… Facebook’s key-value store RocksDB also builds on LevelDB.
HyperLevelDB, HyperDex, RocksDB
This paper was reviewed by The Morning Paper