Queues Don’t Matter When You Can JUMP Them! on NSDI 2015. The authors provided all the source and steps needed to reproduce the results. This is not common in academic system. There is a “Debate: It’s time: academic systems venues should require authors to make their code and data publicly available; those that do not will be held to a higher standard” on ASPLOS 2015.
Many datacenter applications are sensitive to tail latencies. Even if as few as one machine in 10,000 is a straggler, up to 18% of requests can experience high latency. This has a tangible impact on user engagement and thus potential revenue. One source of latency tails is network interference: congestion from throughput-intensive applications causes queueing that delays traffic from latency-sensitive applications.
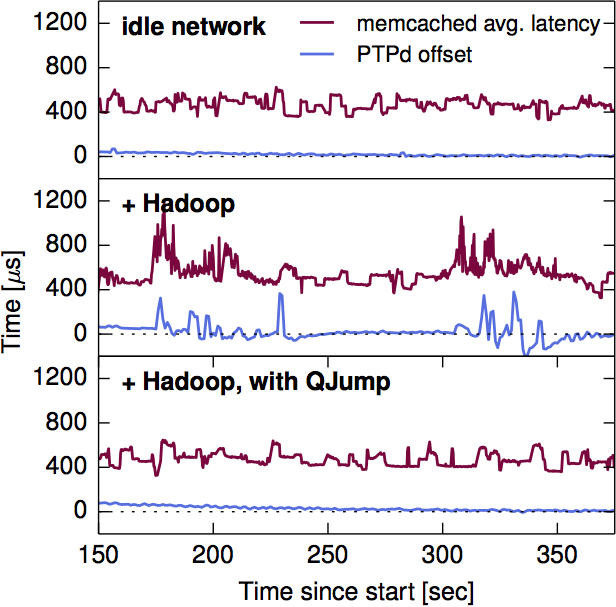
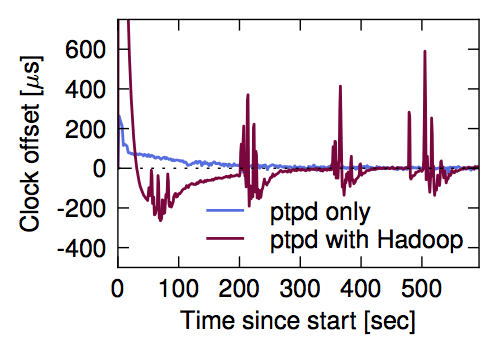
In their evaluation, the authors found that mixing MapReduce and memcached traffic in the same network extended memcached latency in the tail by 85x compared to an interference free network. Similar effects were observed with the PTPd low-latency clock synchronisation daemon, and the Naid data-flow computation framework. This leads to the insight that if the low-latency application packets can somehow ‘jump the queue’ and take priority over the less latency sensitive application packets then we can mitigate these effects. Of course, with enough low-latency traffic we’ll also get interference between low-latency applications as well (due to contention at network switches) – we can solve that problem by rate limiting.
Our exploratory experiments demonstrate that applications are sensitive to network interference, and that network interference occurs primarily as a result of shared switch queues. QJUMP therefore tackles network interference by reducing switch queueing: essentially, if we can reduce the amount of queueing in the network, then we will also reduce network interference. In the extreme case, if we can place a low, finite bound on queueing, then we can fully control network interference. This idea forms the basis of QJUMP.
Suppose a switch has four input ports, a packet arriving at a port will wait for at most three other packets (one at each of the other three input ports) before being serviced. Now consider a multi-hop, multi-host network. Assume that each host has only one connection to the network, and in the worst case with n hosts, n-1 of them can all try to send a packet to the nth host at the same time – this gives a ‘network fan-in’ of n-1. From this we can find an upper bound on the worst case end-to-end packet delay which is given by
(n * (maximum packet size/rate of the slowest link in bits per second)) + cumulative hop delay
We define a scaling factor f so that the assumed number of senders n is given by
n = n/f where 1 <= f <= n
We would like to use multiple values of f concurrently, so that different applications can benefit from the latency variance vs. throughput trade off that suits them best. To achieve this, we partition the network so that traffic from latency-sensitive applications (e.g.PTPd, memcached, Naiad) can “jump-the-queue” over traffic from throughput intensive applications (e.g.Hadoop).
Figure 5 (page 8) shows that QJump is capable of resolving interference in PTPd as well as memchaced.