FLIN: Enabling Fairness and Enhancing Performance in Modern NVMe Solid State Drives
主要讲的是SSD引入Nvme导致的公平性问题
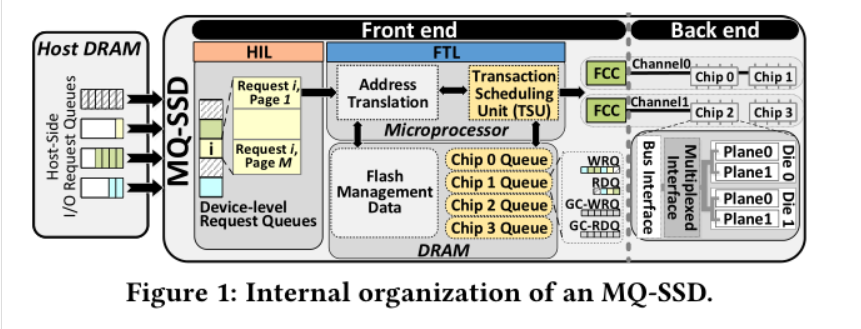
分为前端和后端:前端包括和Host交互的模块和控制模块 后端是数据存储单元 前端HIL的协议与Host进行交互,以轮询的方式从HOST侧获取IO请求 MQ=muti-queue 指的是chip level的队列
处理I/O的流程
1.主机端产生请求,然后插入到DRAM中的请求队列中,一个队列代表一个flow 2.HIL从Host的队列中抓取请求,然后把请求放到SSD的请求队列中 3.HIL解析命令,然后把这些命令分解成事务 4.FTL进行L2P的转换 5.FTL中的TSU(事务调度单元调度)事务进入到不同的chip level队列 6.TSU从这些队列中选取一个发送给FCC 7.FCC把这个事务发送给相应的Chip执行
存在的问题
1.I/O命令的数据长度导致的干扰 小数据I/O在chip level队列长度变长时受到的影响更大
2.有些flow利用了多chip进行了并发,这些flow在与没有利用chip level并发的flow一起执行时受到的干扰更大
3.读优先调度导致的不公平 写在flow中的占比越高,这个flow的公平性越低
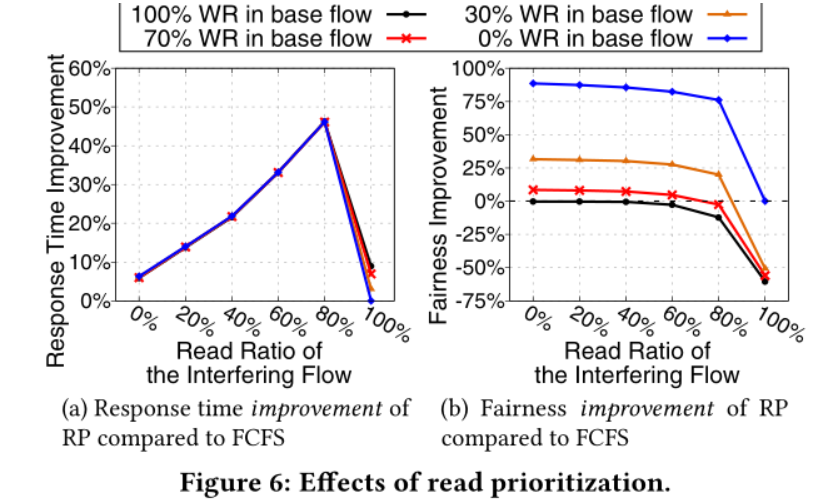
- GC的数量会随着写入量增大而增大,GC-高的Flow会对GC低的flow造成干扰
解决方案
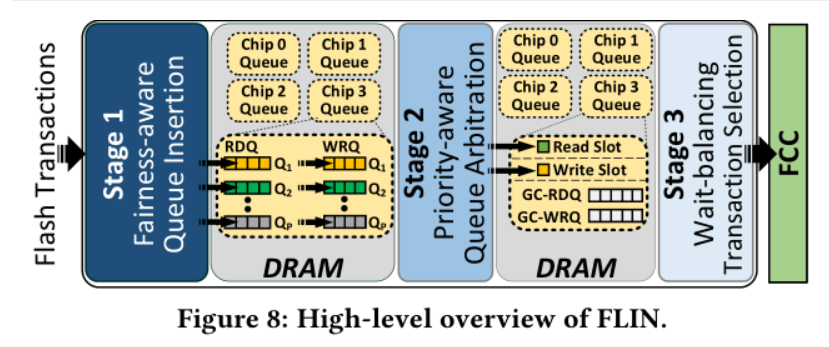
- 解决Low-high I/O intensity以及 并行访问模式干扰问题
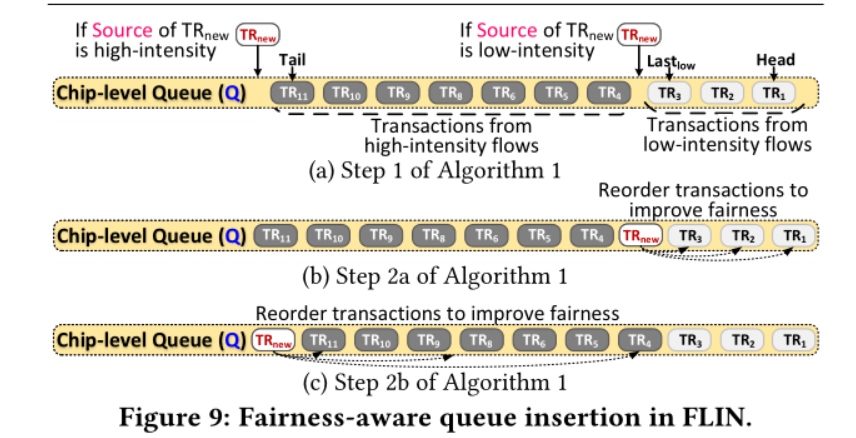 2.从当前优先级P中选取一个准备好的写请求,一个准备好的读请求
2.从当前优先级P中选取一个准备好的写请求,一个准备好的读请求
3.在read write GC-RDQ GC-WRQ中选取一个进行调度 这里调度不是之前的读优先调度,然后计算读写的等待时间来决定时=是调度读请求还是写请求 GC操作的代价可以通过和写一起执行分摊给写事务
提升的点: 当读请求可以随时挂起写事务 读事务可以中断GC请求
与UFS工作的启示
1.chip-level的队列和这里的架构稍微有一点像, 是UFS前端每个LU都有队列 2.这里的非读优先调度是否可以移植到项目中, 终端对于读请求的访问更加敏感,有一个read over write的命令 要具体看一下代码看具体实现是读优先调度还是类似一个flag 3.GC和write是否可以并发 4.read是否可以抢占GC