Asynchronous I/O Stack: A Low-latency Kernel I/O Stack for Ultra-Low Latency SSDs
作者对于IO stack的背景知识讲述,以及motivation的叙述非常的好,推荐阅读原文
introduction
闪存和相变存储器等新技术的提出,现在的SSD可以提供低延迟和高带宽,三星的Z-SSD和英特尔傲腾的SSD可以提供10us的延迟以及3.0GB/S的带宽,那么原有的在内核堆栈中的开销就不能被忽视了。
解决的办法:
1.用户进程直接访问设备 挑战:应用自身需要有块管理层,以及进程之间需要一定的保护
2.优化原有的IO堆栈,使用轮询机制来避免上下文切换开销,在中断处理中移除下半部,提出分散/I/O命令,简单块I/O调度,其中有些被主流采纳了,也就是NVMe SSD中的I/O堆栈
本文发现了进一步优化存储访问中的I/O延迟的机会。当前的I/O堆栈实现需要许多操作来处理单个I/O请求。例如,当应用程序发出读I/O请求时,将在page cache中分配一个页面并建立索引。然后,进行DMA映射,并分配和操作几个辅助数据结构(例如bio、request)。这里的问题是,这些操作在向设备发出实际的I/O命令之前同步发生。在低延迟的SSD中,执行这些操作所需的时间与实际的I/O数据传输时间相当。在这种情况下,如果将这些操作与数据传输重叠可以极大地减少端到端I/O延迟。
于是本文就分析CPU执行哪些命令操作时可以和设备异步进行,节省时间,并且为了进一步的减低块层的开销,提出了一个轻量级的块层
总结一下本文的工作:
1.提供了Linux内核I/O堆栈操作的详细分析,并确定了可以与设备I/O操作重叠的CPU操作
2.提出了轻量级块I/O层(LBIO),专门用于现代的基于nvme的SSD设备,它提供的延迟明显低于普通的Linux内核块层
3.提出了read和fsync路径的异步I/O堆栈,其中CPU操作与设备I/O操作重叠,从而减少了read和fsync系统调用的完成时间(章节3.2和3.3)。
4.随机读性能提高了33%,随机写性能提高了31%,实际负载,rocksDB提高了11-44%的吞吐量
Background and Motivation
瓶颈变化
在原本传统的计算机体系架构中,主要的开销是慢速的存储,现在SSD的速度变快了,瓶颈也有了变化
IO堆栈分层
一个I/O堆栈是由许多层。虚拟文件系统(VFS)层提供底层文件系统的抽象。页面缓存层提供文件数据的缓存。文件系统层在块存储之上提供特定于文件系统的实现。块层提供操作系统级的块请求/响应管理和块I/O调度。最后,设备驱动程序处理特定于设备的I/O命令提交和完成。
读操作的路径
首先读会调用VFS功能,进入到page cache中,它识别请求文件范围内所有缺失的索引,分配页面并将页面与缺失的索引关联。最后,它请求文件系统读取缺少的页面。
文件系统将每个页插入到页缓存中,检索页的逻辑块地址(LBA),并向底层块层发出块请求。
之后是到块层,进行的操作是生成bio object,初始化请求的信息,然后转化为请求对象,插入到请求队列,主要进行的一些调度
设备驱动层:NVMe协议完成请求
read异步执行的动机
有些操作可以和设备IO的时间重叠
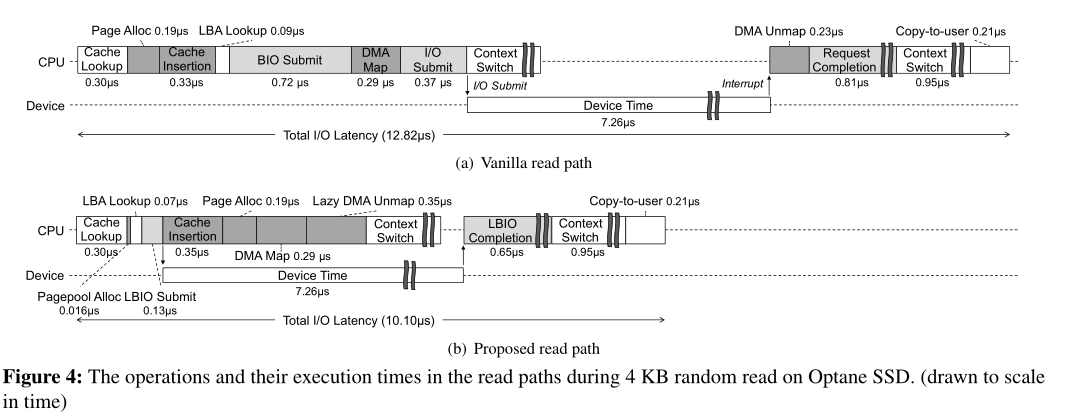
深灰色阴影的部分
写路径
如果是bufferd write的话,那么就不能进行异步,因为不涉及到任何I/O
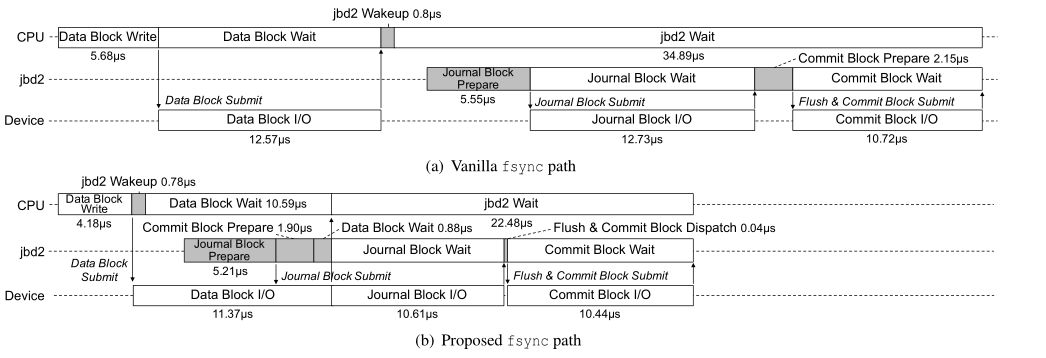
fsync操作的话可以分为3个I/O(ext4文件系统),data block write 日志块写 提交块写
fsync异步执行的动机
轻量级块层的动机
Linux内核默认使用NVMe ssd的多队列块层,可以很好地扩展多个命令队列和多核cpu。这个块层提供了像块I/O提交/完成,请求合并/重新排序,I/O调度和I/O命令标记等功能。虽然这些特性对于一般块I/O管理是必要的,但它们会延迟I/O命令向存储设备的提交时间。
块I/O提交/完成和I/O命令标记是必要的功能,请求合并/重新排序和I/O调度是不重要的。多队列块层支持各种I/O调度器,但其默认配置是noop,因为许多研究报告称,对于快速存储设备上的延迟关键应用,I/O调度在降低I/O延迟方面是无效的。I/O调度也可以被设备端I/O调度能力所替代。在超低延迟ssd中,请求合并/重新排序的有效性也值得怀疑,因为它们的随机访问性能高,并且找到相邻或相同块请求的概率低。
异步IO栈的实现
轻量级块层的实现
用LBio替代的原本的Bio,节省了Bio转换request的开销,LBio记录了LBA 长度等信息
用了一个全局的二维数组来记录LBio,有多少个核就有多少行
每一行的LBio都会映射到NVMe的一个队列中,假设有8核,4个NVMe 队列,那么就两行映射到一个队列中
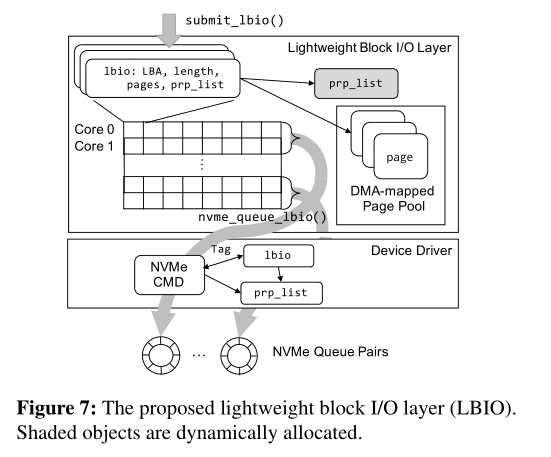
同时没有请求的合并以及调度来节省开销 (PS:感觉这里做的比较粗糙)
读路径实现
预加载了映射关系,节省时间开销
将关键路径中的四个步骤与设备IO时间进行重合
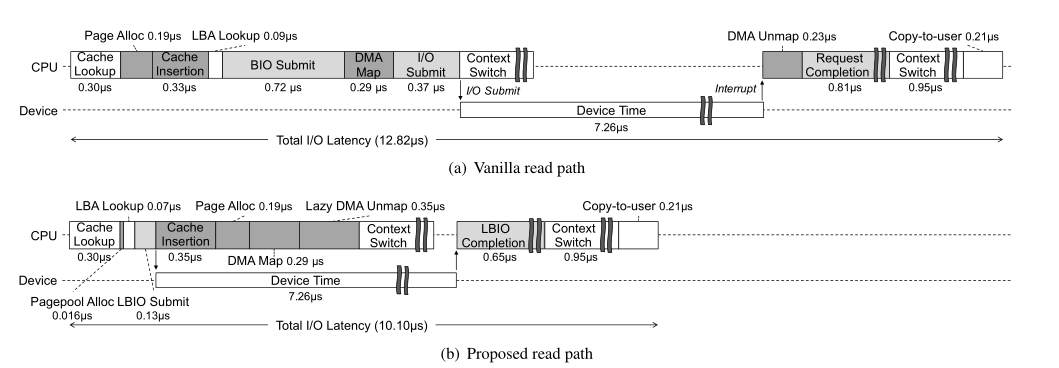
页分配 DMA映射:
提前准备了一个空闲页池,然后在设备IO时进行操作,如果超过则和原来一样操作
页索引:
这里存在一个锁,将这个时间延长,可能会干扰下一个请求。
做法是允许重复的请求,在实现的时候,让一个页面与这个页面进行映射,其他的标记为废弃
DMA解映射:DMA解映射延后会带来DMA缓存区被延长使用的问题,如果没有恶意请求的话可以使用,用户也可以选择禁用
刷新操作路径(写)
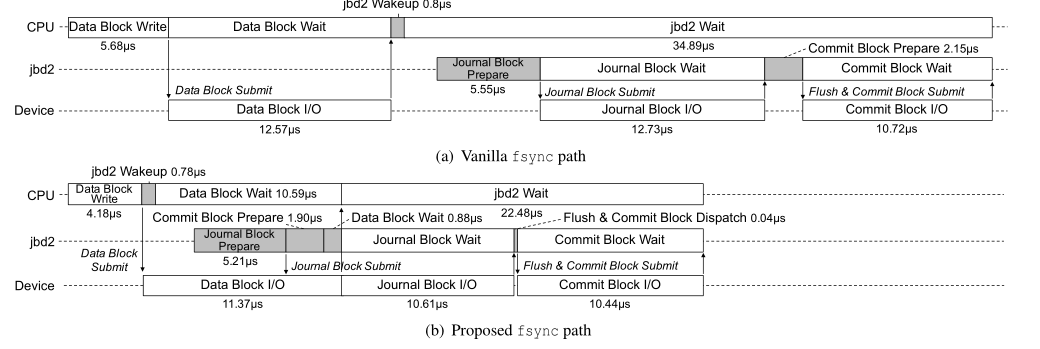
把日志记录操作和设备IO合并