CrossFS: A Cross-layered Direct-Access File System
introduction
底层的SSD延迟已经降低到了微秒级,I/O的瓶颈已经变成了存储软件,学界尝试过从内核级、用户态、固件来提高CPU的并发,还有直接访问存储,以及利用存储的计算能力等方面做优化。但是这些优化都缺乏整体的考量,无法很好的利用低延迟的SSD
内核级文件系统面临的问题:
1.应用程序必须进入和退出操作系统执行I/O,这可能会增加1-4µs的延迟
2.即使是最先进的设计也会在访问文件中不相交的数据部分时强制执行不必要的序列化(例如,inode级读写锁),从而导致高并发访问开销[48]。
3.内核fs设计未能充分利用存储硬件级的能力,如硬件的计算能力、数千个I/O队列和固件级调度,最终影响I/O密集型应用程序的I/O延迟、吞吐量和并发性
用户态文件系统的提出,存在的问题
1.很难从不受信任的用户态满足基本的文件系统
2.仅提供数据平面操作或者是利用继承线程完成并发控制来提供直接访问
固件级文件系统的提出,存在的问题
1.无法利用主机多核
2.IO可扩展性差
提出的方法
提出了一个跨层的文件系统,将文件系统分解成了三层,firm-fs lib-fs以及操作系统层
firm-fs允许应用程序直接访问存储,而不影响基本的文件系统属性,利用存储硬件的I/O队列、计算能力和I/O调度能力来提高I/O性能。
LibFS提供POSIX兼容性,并使用主机级cpu (hostcpu)处理并发控制和冲突解决。
OsFS在LibFS和FirmFS之间建立初始接口(例如,I/O队列),并将软件级访问控制转换为硬件安全控制。
背景知识及相关工作
Kernel-FS:
F2FS利用了SSD的多队列,并且提出了一个日志结构
LightNVM把FTL移到了主机侧
PMFS NOVA利用了NVM的可字节编址
ext4提出了inode level的信号量,提高了并发读访问
以及SPDK NVMe提供直接访问,但是这些都是简单的块操作
User-FS:
提供用户态的库,只提供数据平面的操作
Strata:为每个进程提供数据、元数据缓冲日志
ZoFS:面向的是非易失性内存,使用了虚拟内存来保护数据和元数据缓冲区的访问
存在的问题:需要比较高的开销,使用的粗粒度的锁,扩展性(scalable)不佳
Firmware-FS:
将文件系统或部分放到设备的固件中
允许应用程序绕过OS对数据进行访问,作为一个中心实体协调文件系统的数据和元数据更新
存在的问题:使用了inode级锁处理并发性,限制了文件系统的并发性和可伸缩性
Motivation
现有文件系统存在的问题
1.现有的文件系统缺乏协同性的设计
2.inode级锁会导致可扩展性变差
3.读写必须经过操作系统
吞吐量测试:
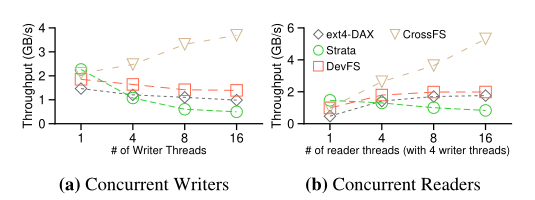
对于一个12GB的文件进行了并行读写访问,测试吞吐量
对于写,ext4-DAX有inode级的锁,strata同样如此,并且还存在一个NVM log buffer记录数据以及元数据的更新,这个缓冲区经常会被填满,导致写操作挂起
对于读(在有写进程的情况下),ext4-DAX有inode级的锁,导致读也不能很好的扩展,strata不仅有inode级别的锁,而且需要等写进程刷新完log 缓冲区后才能让读进程访问,导致吞吐量下降
于是作者提出基于文件描述符的锁
CrossFS的设计
CrossFS设计的原则:
1.将文件系统分解到用户态、固件和系统三层
2.细粒度的并发,基于文件描述符的的并发控制,每一个文件描述符设置一个专门的I/O队列
3.在固件侧实现I/O调度算法,更好的利用设备的CPU
4.在崩溃一致性方面利用了NVM的特性来保护用户数据和文件系统的状态
CrossFS的层级

LibFS:应用通过LibFS使用文件系统的接口,LibFS会将这些操作转化成FirmFS I/O的命令。
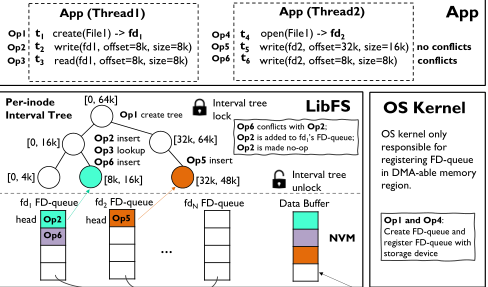
这里引入了一个FD-Queue的概念,如果不存在操作冲突,那么就将操作放入到这个文件描述符的FD-Queue中,当存在冲突操作的时候,会检索inode-tree,然后放到同一个队列中。这个冲突的处理的过程是如果是线程间的,那么由主机CPU完成,如果是一个线程的由设备CPU完成。这里可以这样设计是现在底层的硬件可以支持开辟大量队列。
FirmFS:固件文件系统层,处理从FD-Queue中获取的来自LibFS的请求。这里的设计类似于传统的文件系统,具有内存和磁盘上的元数据结构,包括超级块、位图块、索引节点和数据块。FirmFS还支持使用设备上的专用日志空间进行数据和元数据日志记录。FirmFS从FD-Queue中获取I/O请求并更新内存中的元数据结构(存储在设备的RAM中)。为了确保崩溃一致性,FirmFS将更新记录到存储中,然后检查它们。FirmFS的挂载过程与传统文件系统类似:查找超级块,然后查找根目录。为了调度来自FD-Queue的请求,FirmFS还实现了一个调度器。最后,FirmFS实现了一个简单的slab分配器来管理设备内存。
OS layer:主要用于通过分配DMA内存区域来设置fd -queue、挂载CrossFS和GC。
基于文件描述符的并发控制设计
-
现代的NVMe设备最多支持64K个I/O queue,CrossFS会将每一个文件描述符的队列和硬件的队列对应起来。CrossFS打开一个文件之后,通过ioctl系统调用为这个文件分配一个FD-queue的空间,然后会把这个FD-queue的信息注册到FirmFS上。也会存在比较少见的情况:打开的文件描述符多于64K,那么就要队列复用。现在的CrossFS暂时没有实现这个,只能在关闭文件描述符后重新映射。
-
并发约束:
1.读必须是读取最新的数据块
2.处理跨文件描述符的冲突写
-
并发访问时,如果是跨线程,消耗的资源比较多则交给主机CPU来控制。如果是多个进程的,为了简单和安全,就交给FirmFS来控制。同时引入了时间戳来记录I/O的顺序。在寻找冲突时引入了一个区间树,基于的时红黑树,key就是block的起始、终止区间
The interval tree’s timestamp (TSC) is checked for following cases: (1) for writes to identify conflicting updates to block(s) across different FD-queues; (2) for reads to fetch the latest uncommitted (in-transit) updates from an FD-queue; and (3) for file commits (fsync). The interval tree items are deleted after FD-queue entries are committed to the storage blocks
-
对于并发写,就像图2中展示的一样,op2和op6存在冲突,那么就放到同一个FD-queue中
对于一个块的写冲突,那么就可以简单的把前一个请求标记为no-op进行合并,多个块的写冲突不能如此。对于并发读,为了获取最新的块,需要去搜索区域内的子树
-
fsync必须要确保这个操作之前的所有的文件更新都要被执行,这个操作会被是为barrier operation,要被下发到这个inode的所有FD-queue中
-
元数据的更新会被当做barrier operation。对于创建目录mkdir操作,需要维护一个全局的队列来完成。
崩溃一致性处理
崩溃一致性的处理在文件系统中是一个很麻烦的部分。
FD-queue恢复:
CrossFS主要是利用非易失性内存来进行恢复,将FD-queue的数据保存在Persistent Memory上,维护一个append-only的日志。同时设置commit标志,在请求被下发到FD-queue中时,添加commit标志,在进行恢复时,没有commit标志的请求将被丢弃。interval tree是在主机或者设备的RAM中,崩溃后利用FD-queue进行重建。
多队列文件描述符调度
把硬件和软件I/O调度器合并为一个Firmware上的调度器并为此设计调度策略来有效利用存储设备的计算能力。
参考文章链接:
https://mp.weixin.qq.com/s/BCmllXmG9Xut_T3AOygPmQ
https://nan01ab.github.io/2020/11/FSs-on-New-Hardware.html