When Idling is Ideal: Optimizing Tail-Latency for Highly-Dispersed Datacenter Workloads with Perséphone
Introduction
The latency of requests can be different, some are in 2us, and others like SCAN and EVAL can take 100+ us or 1+ ms. A short request will block behind long requests. For instance, Google reports that machines spend most of their time in the 10-50% utilization range. Related work aims to multiplex the shared resource such as congestion control schemes and CPU schedulers.
key insight: Perséphone takes advantage of parallelism and abundance of cores to solve the long-tail problem. It lets applications define request classifiers and use these classifiers to profile the workload dynamically. It then uses some reserved CPU cores to handle the short request workloads.
DARC Scheduling
Protect short requests at backend servers by extracting their type, understanding their CPU demand, and dedicating enough resources to satisfy their demand.
Challenge:
- Predicting how long each request type occupies a CPU
- low-overhead workload profiling
- queuing delay monitoring
- Partitioning CPU resources among types, retaining the ability to handle bursts of arrivals and minimizing CPU waste.
- enabling cycles stealing from shorter types to longer ones
Scheduling model
Dispatch cores to request type, then use the core to schedule the request of the type queue (first in first serve) but also steal core cycle from long request core
Worker reservation
Disperse requests into different groups depending on their service time. Compute the core for each group and ensure as-sign at least one worker to a group for the extra fractional request of each group, they can be handled by “spillwall” core or steal from the long request core
Perséphone architecture
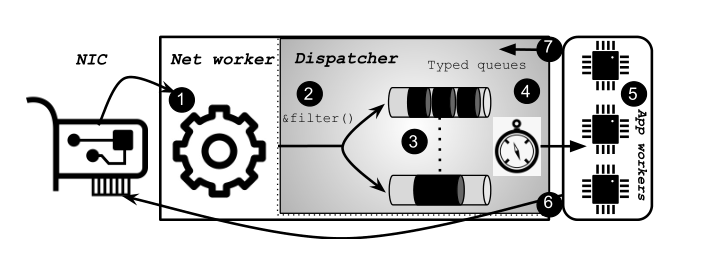
Steps to dispatch requests:
- worker takes packets from the network
- add user-defined classifier for request
- store requests into type queues
- dispatcher give a request to a worker
- worker process the request
- response to the NIC
- dispatch
Evaluation
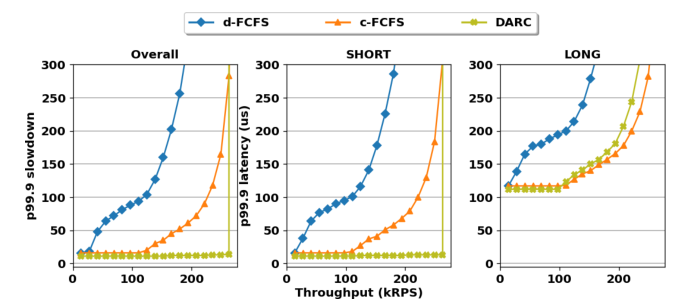
Compared to the d-FCFS and c-FCFS, the overall latency and short request latency in DARC decrease a lot.
Concept of Work-conserving scheduler
In computing and communication systems, a work-conserving scheduler is a scheduler that always tries to keep the scheduled resource(s) busy if there are submitted jobs ready to be scheduled. In contrast, a non-work conserving scheduler is a scheduler that, in some cases, may leave the scheduled resource(s) idle despite the presence of jobs ready to be scheduled.