InfiniFS: An Efficient Metadata Service for Large-Scale Distributed Filesystems
Introduction
现代数据中心文件数量非常多,很容易超过当前分布式文件系统单个实例的容量,因此许多数据中心会分为多个集群,各自运行一个分布式文件系统实例。如阿里云使用数以千计的盘古文件系统,过去Facebook使用多个HDFS集群等。
然而现在的一个趋势是使用单个文件系统实例覆盖整个数据中心,例如Facebook最近引入了Tectonic文件系统,将小型存储集群整合到一个包含数十亿文件的实例中。这样做带来的好处显而易见:1.全局的数据共享,跨数据中心的数据共享更容易实现,无需各种数据迁移、切分策略等;2.更高的资源利用率,消除了多个集群的重复数据;3.更低的操作复杂性,只需维护一个实例而不是多个集群。
Challenge
分布式文件系统是现代数据中心的重要基础设施组件,而元数据服务是大规模分布式文件系统的可伸缩性瓶颈。
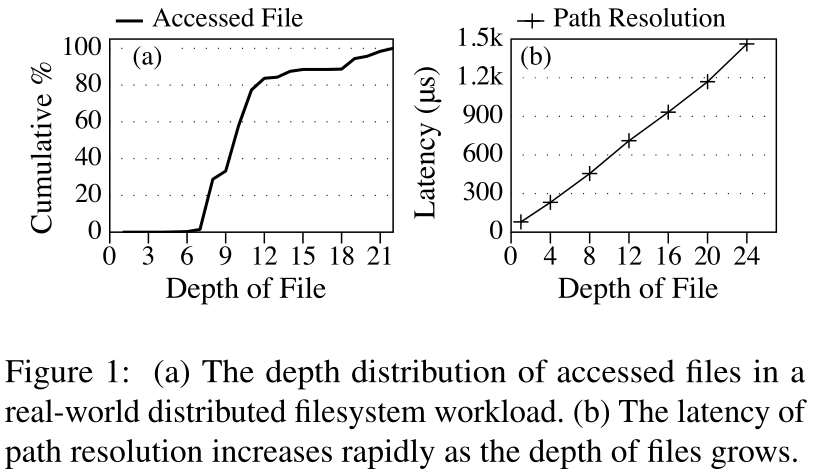
文件系统通常为用户提供分层命名空间(即目录树)来管理文件。在目录树中,每个文件或目录都拥有元数据信息。元数据操作通常涉及两个关键步骤,即路径解析和元数据处理。当用户访问路径名为/home/Alice/paper.tex的文件时,元数据的访问方式如下:首先,文件系统执行路径解析来定位目标文件,并检查用户是否具有适当的权限;然后,文件系统执行元数据处理,以原子方式更新相应的元数据对象。
一个跨越整个数据中心的大型文件系统需要支持数十亿个文件,并为大量客户机提供服务。这给分布式文件系统的元数据服务带来了严峻的挑战:
-
实现目录树分区的高元数据局部性和良好的负载平衡具有挑战性,因为同时存在目录树的可扩展性需求和工作负载的多样性;
-
路径解析的延迟很高,因为在超大规模的文件系统中,文件深度很深;
-
客户端元数据缓存的一致性维护开销变得巨大,因为超大规模的文件系统通常需要为大量并发客户端提供服务。
Background
元数据的组成:
- 访问元数据:包含目录名,ID,权限,用于访问目录树的信息
- 内容元数据:entry list,时间戳等,和子节点更相关的数据信息
元数据操作分类:
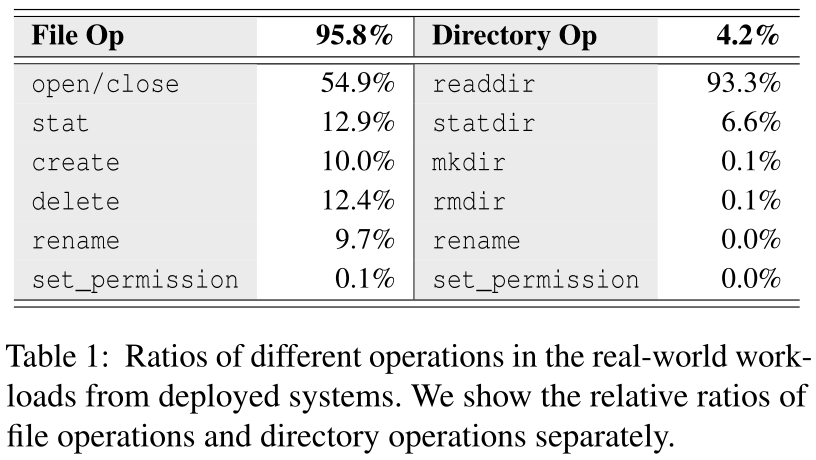
- 仅处理目标文件/目录元数据的操作,如 open、close、stat 等;
- 处理目标文件/目录及其父文件/目录元数据的操作,如 create、delete、readdir 等。例如,create 将首先插入文件元数据,然后锁定和更新父目录的 entry list 和时间戳;
- rename 操作是特殊的,因为它处理两个文件/目录及其父文件的元数据。
- 第一类和第二类为大部分操作,需要在元数据处理过程中获取对应目标文件/目录的元数据。
Design
设计概览如下图:
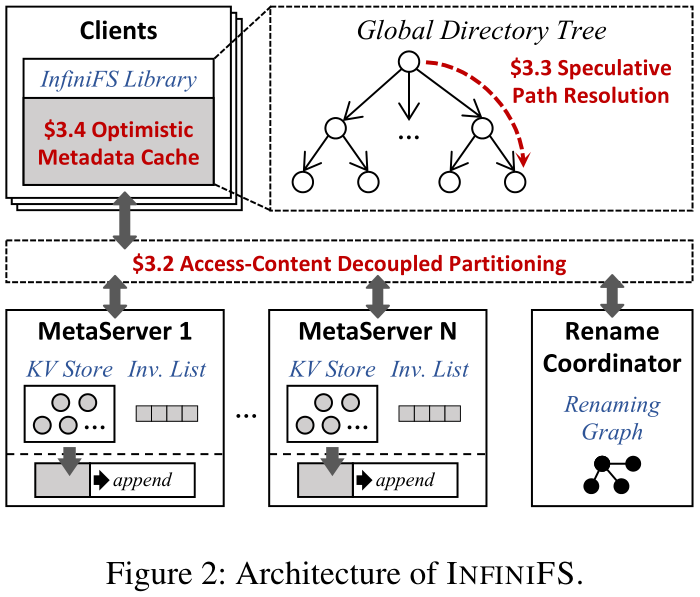
总体而言,作者进行了三个设计:访问-内容解耦的元数据分区(客户端服务端交互)、基于推测的路径解析(客户端)、乐观访问元数据缓存(客户端)。
访问-内容解耦的元数据分区
通过对问题的分析,作者发现以前的文件系统无法兼顾局部性和负载均衡的原因:把目录元数据视为一个不可分割的整体。
目录的元数据的不同部分实际上是分别与父目录及子目录相关的,可以将目录元数据分为访问元数据(目录名、目录ID和访问权限)和内容元数据(条目列表、时间戳等)。其中,访问元数据通常与父目录相关,而内容元数据通常与子目录/文件相关。
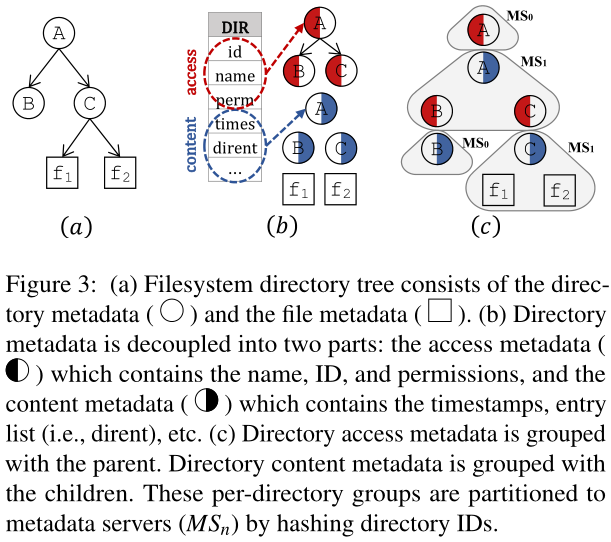
基于局部性的考虑,可以将父目录的内容元数据与子目录/文件的访问元数据分为一个目录组,放置到同一个服务器中。
基于负载均衡的考虑,通过哈希散列将目录组划分到不同的元数据服务器上。
基于推测的路径解析
传统的路径解析是串行的,解析了上层目录才能向下层目录/文件继续解析,因此解析的开销与目录树的深度呈正比。这在深度较小的单机环境下是可以接受的,但是在大型数据中心中,目录树深度很深,且不同目录的元数据可能存在于不同服务器,引入了和解析路径长度正相关的网络开销。
如果能对路径中的每个目录进行并行解析,那么就能成倍降低路径解析以及网络的开销,如下图所示。
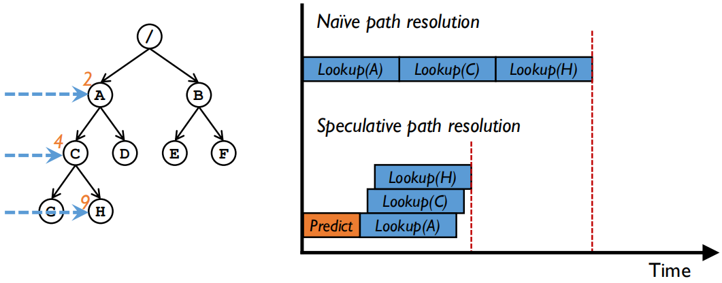
因此作者提出了基于推测的路径解析方法,给每个目录赋予一个ID,每个ID根据<父目录ID,目录名,版本号>通过哈希(如SHA256)生成。(版本号用于解决rename时出现的一个特定问题orphaned loops,同时引进了一个小设计-重命名协调器,可见论文原文4.1节)
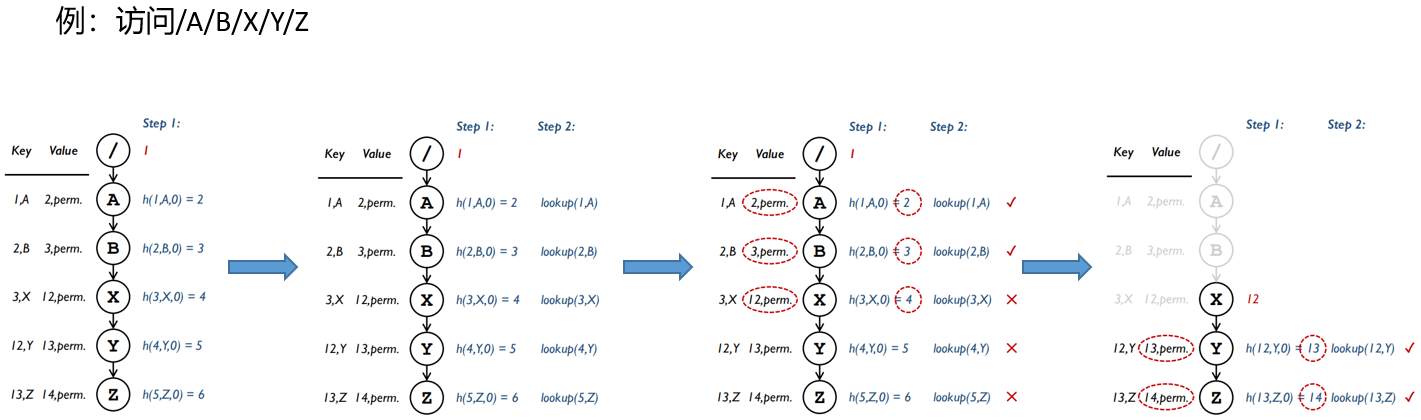
进行路径解析时,客户端首先读取其路径缓存,获取待解析路径中已知的目录ID,然后根据路径中最右侧的已知目录ID迭代地推测更右侧的目录ID,全部计算完成后将每个推测的目录发往元数据服务器进行核对,如遇到推测错误的目录则进行更正并重新推测。
例如下图,客户端已知根目录的ID并且根据其进行路径推测,第一次推测命中了两个目录,核对并更正X的目录元数据后再次进行推测并正确,成功完成了路径解析,相比传统串行路径解析减少了约五分之三开销。
乐观访问元数据缓存
这部分设计比较简单,就是每个客户端拥有一个惰性失效的访问元数据缓存。当目录元数据修改时,元数据服务器不主动通知各个客户端,而是在客户端向服务器端发送查询时再告知其元数据的修改,然后客户端获取有效的元数据并且更新其缓存。
Evaluation
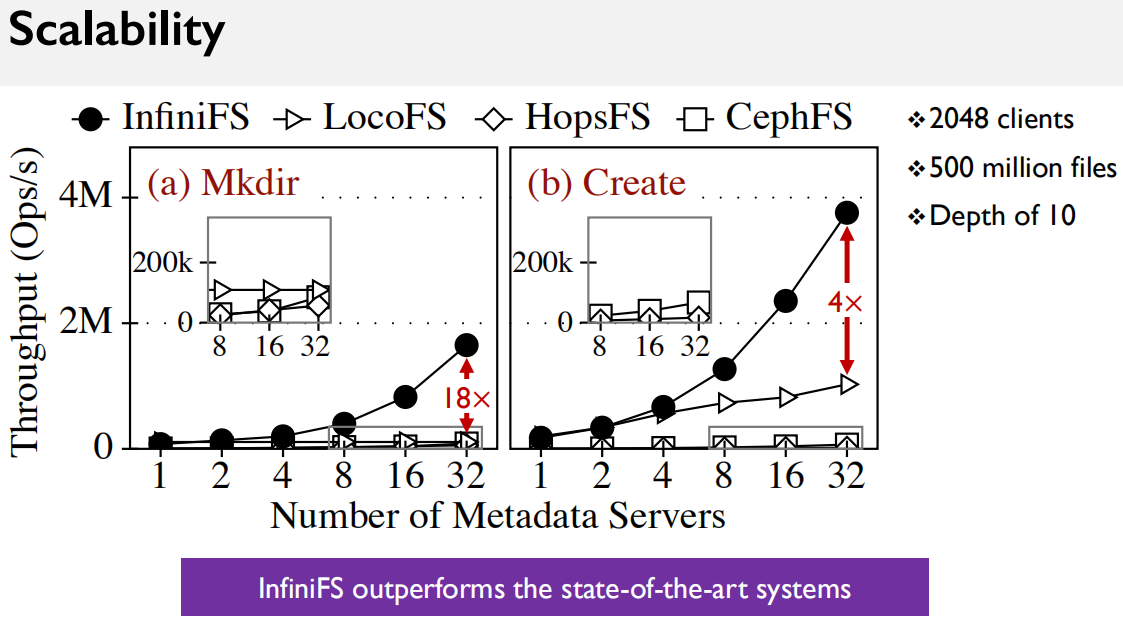
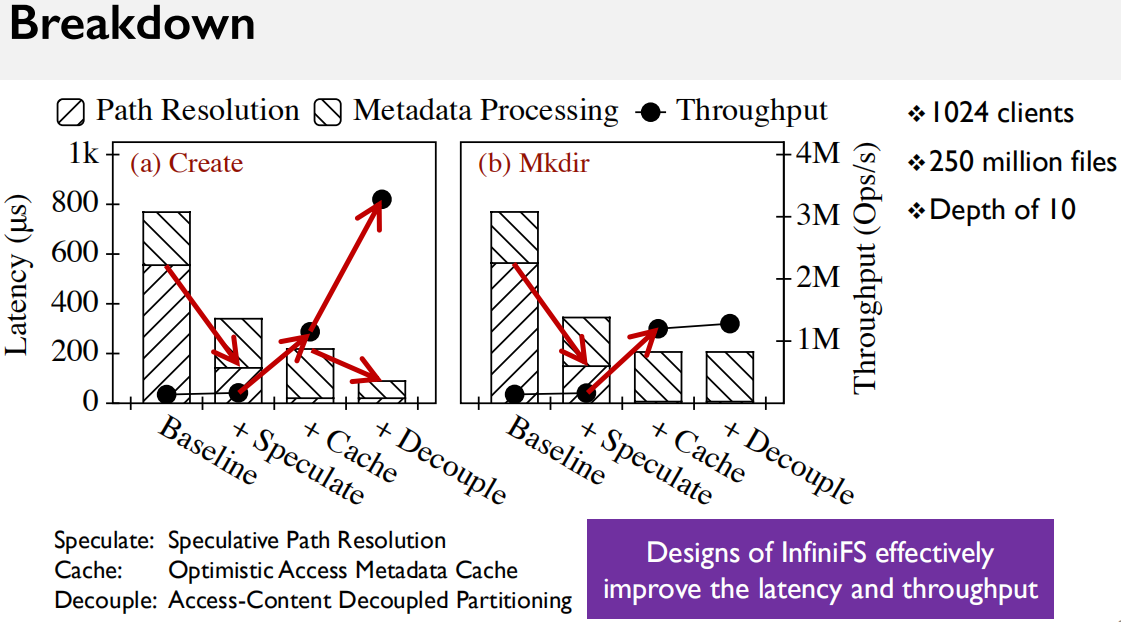
Thought
这篇论文从一个非常实际的问题出发,尝试解决大型数据中心级别的文件系统元数据如何维护的问题,并且给出了一个有新意的设计:将目录元数据进行更细的划分。这提醒我们同一个数据结构的成员并不是具有同样的局部性,有时候进行更细粒度的划分可以带来更好的局部性以及负载均衡。
另外论文将串行的路径解析通过哈希和算法实现了并行化推测,这点和reject有点点类似。