Optimizing Memory-mapped I/O for Fast Storage Devices
Introduction
快速存储的出现正改变着IO的格局,SSD可以更好的处理小型随机IO让应用程序可以更好的进行数据管理设计,但是大量小数据的IO对于内核IO路径也会导致CPU的开销显著增加。
在这种情况下,mmap在命中的情况下不会产生额外的开销,相比于读写io性能更好受到了更多的关注。然而,实际的情况是mmap会产生大量的随机小IO。虽然性能好的设备例如Nvme一般可以忽略这个问题,但是当系统中处理器数量很多时,设备的压力增长,这个问题就不能被忽略了。
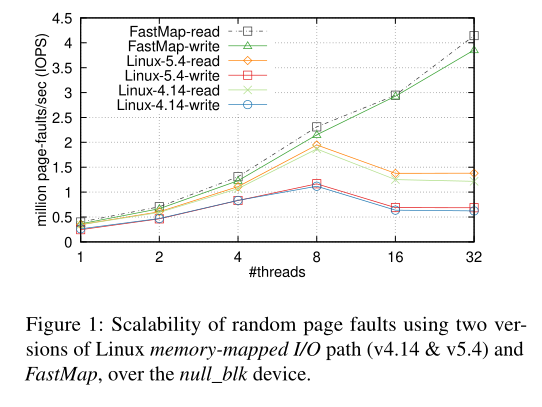
上图是linux系统中线程数量上升时,系统在使用mmap IO时,可以处理的page fault量,可以看到线程的数量大于8时,无论时4.14版本的内核还是5.14版本的内核,page fault的IOPS都明显下降了。
Design
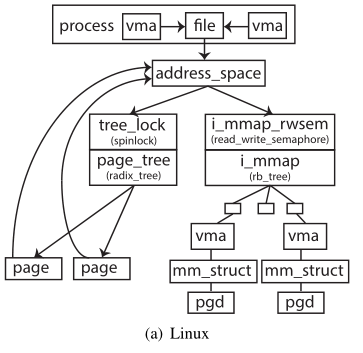
Linux下,现有的映射结构如上图所示,每个进程的虚拟地址空间对应这一个VMA,每个VMA指向一个file,代表对应的对应映射的起始偏移。每个file又指向一个共有的地址空间,里面包含映射的page信息。这里的immap管理的是指向这个address_space的所有VMA。
FastMap提出了一个优化的映射结构,如下图所示
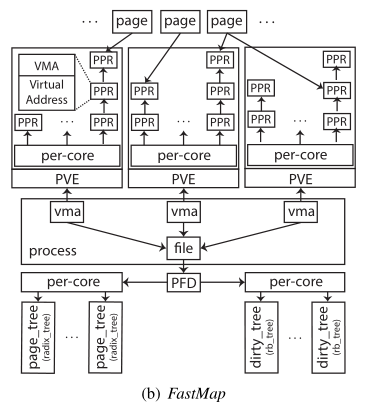
PFD=Per-File-Data,PVE=Per-Vma-Entry,PPR=Per-Pve-Rmap
核心分为两个部分,一个是优化page_tree的锁结构,另一个是优化反向映射方面,提出了一个更细粒度的锁。
PFD
在Linux中,page tree用来追踪与某个文件的所有页面,包括脏页和非脏页,这个page tree是由所有线程共享的,访问需要自旋锁,显然这就是影响多线程的因素,FastMap让每个CPU都维护一个page tree来取缔这个自旋锁,从而让page tree的锁粒度更细了。
PVE
反向映射在Linux一般用于写回和unmap,在Linux下现有的i_mmap结构存在两个问题
- 存在额外的页表遍历开销
- 迭代时需要粗粒度的锁
针对这两个问题,FastMap提出了PVE(Per-Vma-Entry)结构,里面维护了每个VMA的反向映射,这样锁的粒度就可以到VMA级。
evaluation
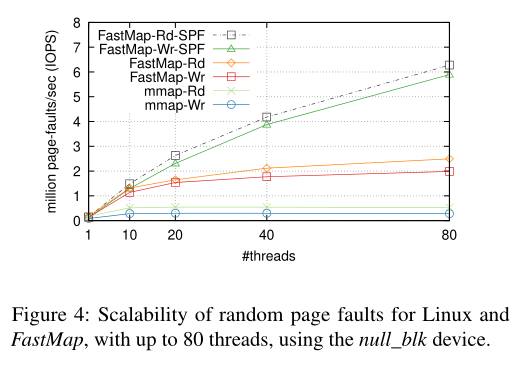
与现有的Linux的mmap机制相比,优化page tree和反向映射后,FastMap可以在40~80 thread的情况下保持很好的性能。