Fine-Grain Checkpointing with In-Cache-Line Logging
Introduction
传统的故障恢复开销很大,需要从硬盘或者是磁盘恢复数据。随着非易失性内存的出现,主存和外存的边界模糊了起来。NVM可以字节访问,并且掉电不丢失,如果从NVM中恢复数据开销可以小很多。
但是如果从NVM进行故障恢复就要面临和cache的一致性问题。因为cache是掉电丢失的,如果crash,那么没有保存到NVM的数据就丢失了,并且cache的下刷并不是按照系统的写入顺序的,而是取决于cache的替换策略。
解决这个问题,学界主要两种思路,一种是事务机制,保证日志全部下刷后,再进行实际数据的更改。另一种是检查点机制,周期性的保存现在运行系统的状态。事务机制的日志下刷开销很大,检查点机制如果保存的频率较大同样会影响性能。
本文提出了一种细粒度的检查点机制,将系统的执行分为不同的周期,在每个周期开始之前进行cache的下刷,如果在周期之间崩溃,恢复到上一个周期结束的状态。与之前检查点不同的是,它并不保存数据结构的备份或者是镜像文件,在NVM的数据结构本身就作为检查点。这样的话,在崩溃之后,就存在两种状态,一种是需要恢复的上一个周期的状态,另一个是在这个崩溃周期需要舍弃的操作,如果还是用log机制去区分两种状态,开销同样很大。 本文提出了一种在cache-line中log的方式,避免了下刷的开销。
Background
PCSO(Persistent Memory Ordering Model)
对于不同的cache line的写回顺序保证,需要使用x64的下刷指令和fence指令,开销比较大 对映射到相同cache line的写回顺序保证,只要保证写指令的顺序,相比跨line的比较简单
Formally, given two writes X and W , we say that X <p W if X is written to persistent memory no later than W . X <hb W is the standard happens before relationship. c(X) represents the cache line address X writes to. The following holds [9]:
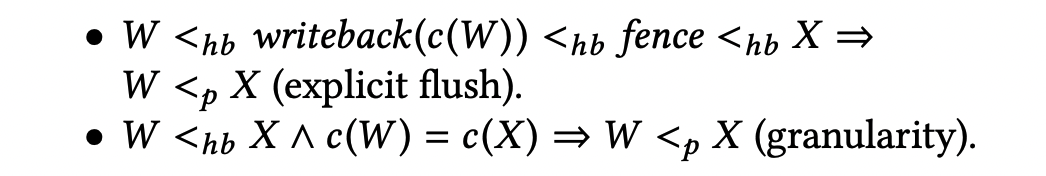
MassTree(EuroSys12)
https://www.modb.pro/db/103351
https://zhuanlan.zhihu.com/p/271740123
Design
本文的主要工作分为三个部分,分别是支持细粒度的检查点、外部日志以及cache line内日志
fine-grained-checkpoint
本文将检查点的备份周期设置为64ms(可以调整),在每个周期开始之前对cache整个cache进行下刷,因为最多下刷cache大小的数据,以及大量的修改都在之前的周期中被完成了,所以开销很低
external-logging
external-logging并不常用,用于记录复杂修改的节点,即InCLL不能处理的情况(同一个缓存行中有两个value被修改)。这里采用了node粒度的锁去避免争用,在node粒度上去记录修改。
InCLL(in-cache-line logging)
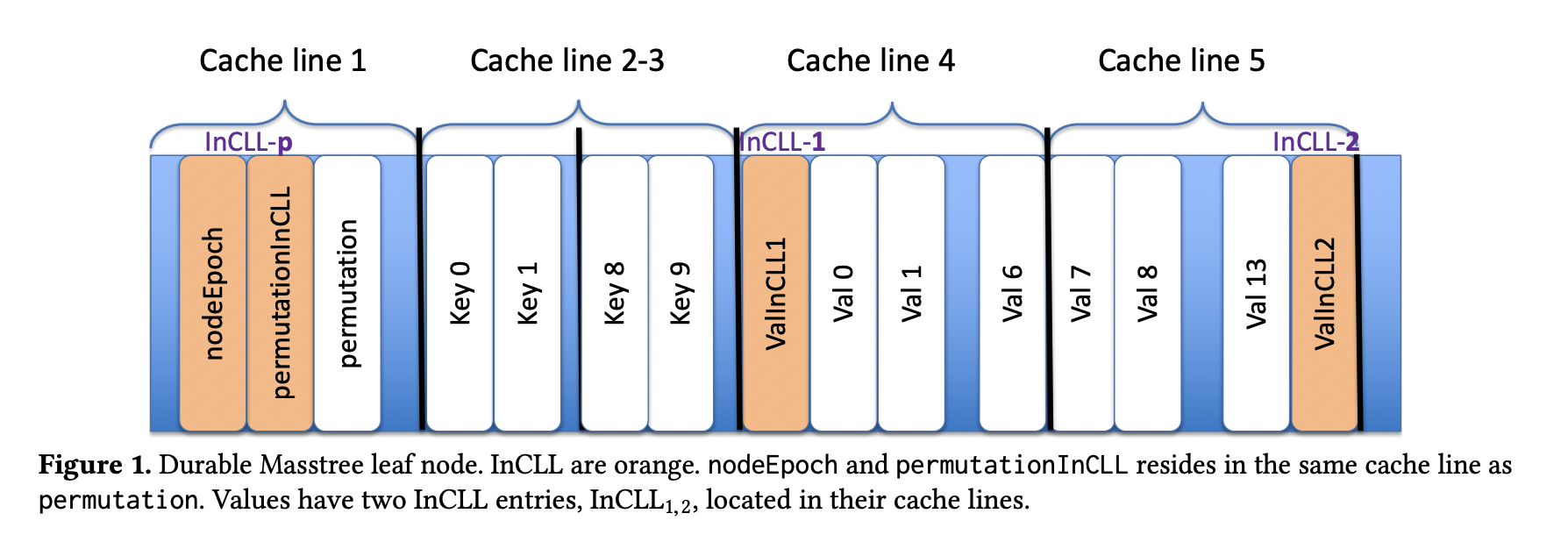
如上图所示,一个node节点中存在三处InCLL,InCLL-p InCLL-1 InCLL-2
InCLL-p记录permutation区域和周期数,permutation区域是masstree记录key-value是否active的值(类似于bitmap)。
InCLL-1 InCLL-2分别记录两个cache line中对应哪个value值的变化,如果是同一个value在一个周期内多次变化,那么就只记录一次。
Conclusion
-
in-cache-logging 降低了cache下刷的次数
-
检查点周期机制降低快照的开销