1、名词解释
DRAM:DRAM(Dynamic Random Access Memory)是一种计算机内存类型,用于临时存储数据和指令,供中央处理器(CPU)快速读取和写入。它是一种易失性存储器,需要不断刷新以保持数据的稳定。DRAM由存储单元组成,每个存储单元通常由一个电容和一个存储位(位线)组成,通过电容的充放电状态来表示数据的0和1。由于电容内的电荷会逐渐泄漏,因此DRAM需要周期性地刷新以保持数据的完整性。DRAM具有高密度、低成本和快速的随机访问能力,广泛应用于计算机系统和其他设备中。DRAM是一种按需刷新的内存,意味着每次访问存储单元时需要定期刷新电容。这与SRAM(静态随机存取存储器)不同,后者不需要刷新操作。由于刷新操作会消耗一定数量的能量,因此DRAM在功耗方面相对较高。
In-memory DBMS :假定数据存储在内存中的。数据以block的形式组织起来,并把定长的数据和不定长的数据分开存储。把锁和数据存在一起,可以更快的判断数据有没有上锁。而disk-oriented databse把锁和数据分开来存。
OLTP:测试系统性能的一个方法。具体包含(1)实现大量人员实时执行大量数据库事务;(2)需要快速的响应时间;(3)频繁修改少量数据,通常涉及读写平衡;(4)使用索引数据来缩短响应时间;(5)需要频繁或并发数据库备份;(6)需要相对较少的存储空间
2、研究背景
In-memory DBMS系统表示所有数据都必须保存在内存中,如果数据集增长,则需要更大的内存容量。但是容量的价格和数据不成线性增长,64GB的DRAM比16GB的贵了7倍。而且,自2012年以来,主存价格开始停滞不前,而数据集的大小却在不断增长。本文提出的系统为了降低成本+处理大数据
3、系统简介
ScaleStore的核心是一种分布式缓存策略,它可以根据工作负载动态地决定哪些数据(数据以页面的形式存在,例如一页为4KB)保存在内存中(哪些保存在ssd上)。1)实现了新型分布式缓存协议,提供了跨机器和存储设备的透明页面访问,线程可以像在非分布式系统中一样访问所有页面,2)同时在多个节点上动态缓存DRAM中频繁访问的页面。 3)分/布式缓存协议跨节点集群协调页面访问保存数据的一致性
4、主要组成部分
1) Worker Pool、2) Translation Table、3) Message Handler、4) Page Provider
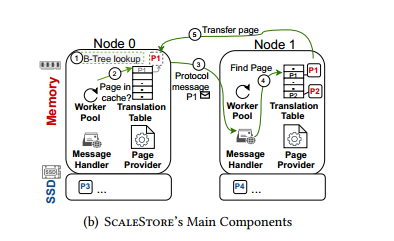
节点如果需要某个页,流程如下:worker pool 中的某个线程先去本地缓存中寻找,如果在,则取出来,否则,到Translation Table中去查询该页对应的目录节点(该节点知道一切关于这个页的信息),通过RDMA发送到对应节点的Message Handler程序进行处理,最后由Page Provider进行页面的发送。
5、页面的两种存在模式
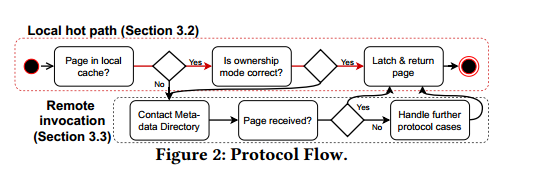
Local hot path
不涉及任何远程消息的快速路径,所有的决策都能在本地做出
第一步:检查页面的所有权模式,节点独占(修改)或者节点共享(访问)
第二步:页面模式正确,会将页面返回给想要获取的线程,其中将涉及到混合锁的机制
- Exclusive:节点独占模式,页面固定,一直保留在本地缓存中,直到解锁
- Shared:节点共享或者节点独占,固定在本地缓存中
- Optimistic:不获取锁的情况下读,页面不固定,可以删除
Remote Invocation
目录节点的确定方式:首次创建该页面的节点
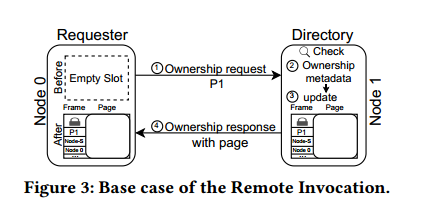
正常情况下,需要这个页面就会去目录节点找,没有冲突的情况下就会更新并返回。冲突会在第二个步骤,这个页面当前的状态。如下表所示:

遇到冲突之后,目录节点就会告诉需求者你去找该页面的节点,再进行沟通。注意不需要向目录节点发送确认消息,采用即时元数据更新的技术
shared conflict 冲突的处理:目录节点给requester提供一个缓存了该页的节点列表,requester随机选择一个节点让它把页面传送,随后告诉所有的节点这个页面我独占了!
多节点冲突
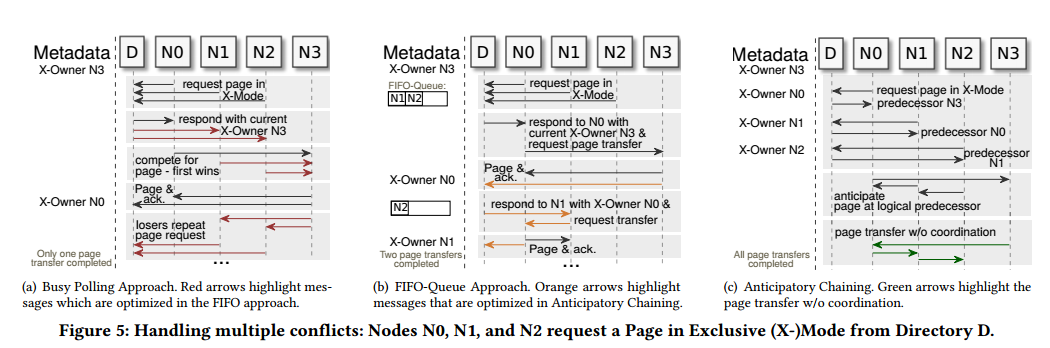
1)朴素的解决办法:D最先收到谁的请求就处理谁的,比如是N0,然后别的节点去找N0,不断的重复查询,N0你用完了吗?
2) 采用FIFO-Queue:将请求放入队列中,一个一个来处理。存在的问题在于如果本地线程访问,就不需要排队,会导致对N0-N3不公平。但是将本地线程放入队列会导致效率低下的问题
3) 作者提出的Anticipatory Chaining:
关键思想:一旦请求页面,就直接更新目录上的元数据。省去了节点要向目录节点发送页面更新消息的步骤
稳定性保证:N1排在了N0后面,N0用完了就把这个页面丢了,这时候N1就找不到页面在哪,后续排队的一切节点都需要重新去找D要页面的位置。为了解决该问题,给每个页面都新增了一个冲突记录。当冲突记录匹配的时候,表示没有节点排队了,D才允许N0进行页面丢弃。否则必须等待。
死锁保证:也是利用冲突记录,具有较低冲突记录的节点需要退出。
测试结果:
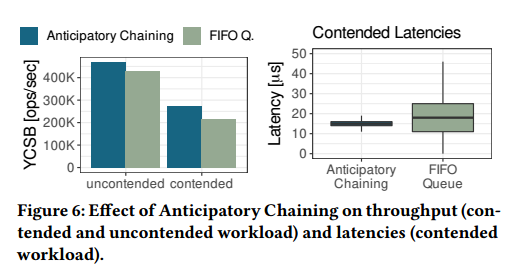
6、实验
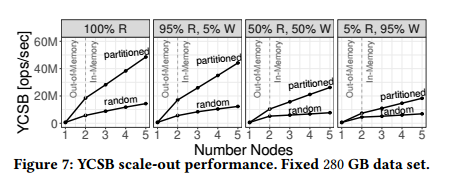
采用5个节点进行OLTP的测试,每个节点有150GB的缓存,数据范围是280GB。partitioned表示工作负载分区,每个节点只缓存部分数据。random表示每个工作节点需要访问完整的范围
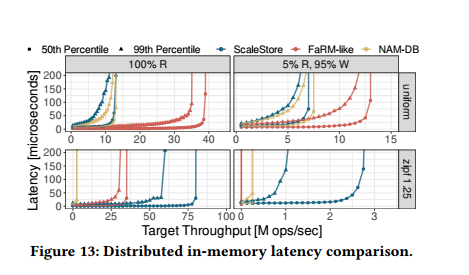
横向对比别的系统例如FaRM-like和NAM-DB有一个较小的延迟
7、总结
这篇文章提出了一个新的分布式存储系统,利用NVMe进行页面的快速换出,利用RDMA进行多节点间的消息传递,降低了数据传输的延迟和提高了吞吐量,有效地降低了硬件成本。 本文的亮点在于提出了新的分布式存储协议,规定了在多节点间数据传输的过程以及如何解决页面锁机制存在的冲突。但是文章没有讨论如果当节点发生故障之后的解决方案。