1、概念解释
INFINSWAP概述: 远程内存分页系统,将每台机器的交换空间划分为许多片,并将它们分布在许多机器的远程内存中,有机会收集未使用的内存,并透明地向未修改的应用程序公开
block device: 交换空间的块设备,在换页的时候将丢弃的页面放回这里
daemon: 管理远程可访问内存的守护程序
尾延迟(tail latency): 尾延迟则是指在一组请求中,延迟最高的一部分请求的延迟时间。它主要关注的是系统中一小部分请求的响应速度,通常是最耗时的几个请求。尾延迟的值可以用来评估系统的稳定性和可靠性,特别是在需要处理实时或高并发请求的场景下。
中位延迟(median latency) 中位延迟是指在一组请求中,将这些请求按照延迟从小到大排序,然后取出中间位置的延迟值。它可以用来表示系统的整体响应速度,即大部分请求的响应时间。
2、背景
内存密集型应用程序的工作集不能完全加载进内存中时,性能的损失会很大。然而,即使在集群内存利用率严重失衡的情况下(失衡的原因在于很多应用程序经常高估它们的需求或试图分配最大内存使用,作者多两个大型生产集群进行分析,超过70%的时间内存利用率存在严重的不平衡),它们也无法在向磁盘分页时利用未使用的远程内存。现有的存储分解提议需要新的架构、新的硬件设计和/或新的编程模型,这使得它们不可行
3、以往的办法
向所有机器展示一个全局内存库,增加有效内存容量。存在需要新的架构,新的硬件设计和新的编程模型的问题 以前也有这种利用内存不平衡和磁盘网络延迟差距进行远程内存分页,但是会导致高的远程CPU开销、中央协调寻找空闲内存的机器的可伸缩问题,以及由于远程内存的逐出和故障而导致的大的性能损失。
4、模型细节
4.1 Memory Disaggregation via INFINISWAP Block Device
slab 管理
INFINISWAP块设备在逻辑上将它的整个地址空间划分为多个固定大小的片(SlabSize),每个slab开始于都是未映射状态。
$
A~current~(s) = aAmeasured(s)+(1-a)A~old~(s)
$
A(s)表示每秒多少次的页面I/O请求,设置了一个hot阈值(20),如果超过这个值,就把这个页面映射到远程机器的内存中去。为了跟踪是否可以在远程内存中找到某个页面,维护所有页面的位图,页面被写入远程存储器之后,将其位设置。当某个片的远程机器出现故障时,或者当某个片被守护进程驱逐时,与该片相关的所有位都会被重置。还有cold slab阈值,低于这个值会被移出。
Remote slab placement
规则:1、在尽可能多的远程机器上分发来自同一个块设备的数据片,防止机器故障带来的损失(鸡蛋不能放在同一个篮子里)。2、平衡所有机器的内存利用率,最小化驱逐的可能性。3、必须是去中心化的,以便在没有中央协调的情况下提供低延迟映射。先选择没有Slab放置的机器,在选择放过的。
I/O Piplines
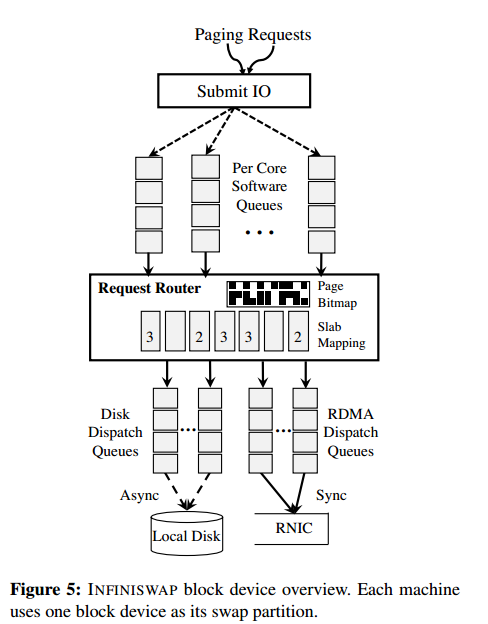 批处理 page write/read请求,一直等待,知道该批次中所有页面上的操作在不同源中完成。写的时候如果有映射,就把请求复制(也要写入磁盘)到RDMA写入远程内存,否则就只写入磁盘
Handing Slab Evictions
守护进程接收到消息之后就将slab标记为unmapped,同时将位tu更改,未来所有的请求都去硬盘中寻找。等待正在进行的调度完成,然后发送一个Done的信息。如果A(s)高于HotSlab,会立即开始重新映射slab。
Handing Remote Faliures
检测到故障时,块设备将该机器上的块标记为未映射,重置位图的相应部分。如果是写后读这样的请求,P被写入远程存储器之后,在写入磁盘之前,远程机器坏掉了。如果VMM试图将P页调入,位图将指向磁盘,并且磁盘读取请求将被添加到磁盘分派队列中
批处理 page write/read请求,一直等待,知道该批次中所有页面上的操作在不同源中完成。写的时候如果有映射,就把请求复制(也要写入磁盘)到RDMA写入远程内存,否则就只写入磁盘
Handing Slab Evictions
守护进程接收到消息之后就将slab标记为unmapped,同时将位tu更改,未来所有的请求都去硬盘中寻找。等待正在进行的调度完成,然后发送一个Done的信息。如果A(s)高于HotSlab,会立即开始重新映射slab。
Handing Remote Faliures
检测到故障时,块设备将该机器上的块标记为未映射,重置位图的相应部分。如果是写后读这样的请求,P被写入远程存储器之后,在写入磁盘之前,远程机器坏掉了。如果VMM试图将P页调入,位图将指向磁盘,并且磁盘读取请求将被添加到磁盘分派队列中
4.2 Remote Memory Reclamation via INFINISWAP Daemon
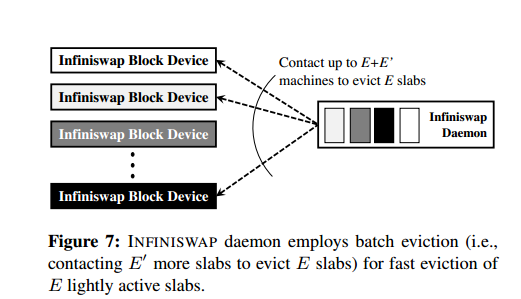
设定一个HeadRomm最低的内存使用量,如果剩余的内存量超过这个值,就把slab都设置为unmapped,这样就减少了计算的这一步,加快速度。否则就需要采用算法去进行slab收回。选择批次收回,要收回E个slabs,选择E+E’个slabs,E’<=E,然后从中选择E个最不活跃的slabs进行驱逐。
5、总结
系统由块设备和守护进程组成,存在于每台机器中。将块设备的整个地址空间在逻辑上被划分成固定大小的片(SlabSize)。设备的数据片被映射到多个远程计算机内存当中,应用程序可以像使用本地内存一样使用这些数据片。需要处理slab的替换和故障检测等问题。