0、术语解释
LSM trees: LSM Tree解释
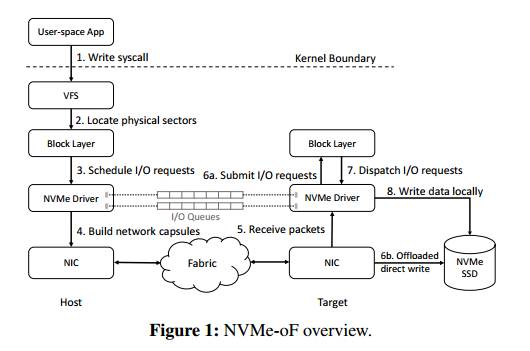
NVMe-oF 示意图
1、背景
键值存储将很大一部分计算资源花费在后台压缩上,对磁盘上的数据进行重新平衡和垃圾收集。在键值存储的情况下,每台机器会将接收到的副本数据进行重新压缩(LSM Tree上的压缩),这些操作会占用大量cpu的时间。不如一开始在一台机器上压缩之后,将压缩的数据发给其他的机器。
2、挑战
1、增加网络带宽。
解决办法:现代数据中心中的网络流量通常未得到充分利用;例如,阿里巴巴[1]和雪花[47]的聚类跟踪显示,50%-75%的网络容量一直处于闲置状态。所以不存在增加网络负载的情况。
2、使用tcp进行文件传输增加两端处理tcp包的成本。
解决办法:使用NVMe-oF,这是一种网络存储协议,可以最大限度地降低辅助节点的CPU成本
3、使用NVMe-oF存在的两个挑战。
3.1 远程节点的本地文件系统不参与文件的写入,不知道更新的文件及其位置
3.2 远程节点上运行的键值应用程序也必须与传入的文件同步,需要更新其内存中的数据结构
2 、创新点
设计了新的机制来解决对复制数据使用NVMe的挑战,包括静态文件的预分配,一种新颖的文件元数据映射机制以及一种强制跨副本应用版本编辑顺序的新方法。
4、系统组成
4.1 Replicator Layer
两个作用:1、将请求路由到包含所请求的键值对的组的副本节点 2、检测和恢复失败的复制
维护一个元数据表,请求来了根据key在表格中的映射发送到对应的节点
4.2 Replication Groups
解决3.1中的挑战: 在运行之前,在从节点中预先分配号多个文件池,主节点将SST文件写入这些文件池中。
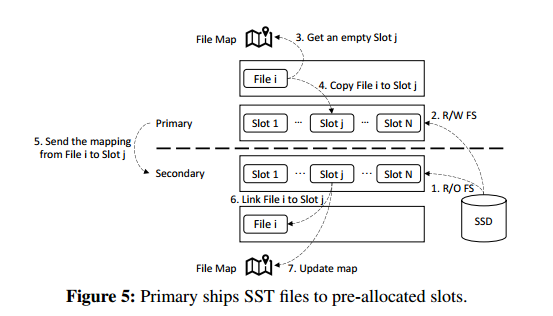
解决3.2中的挑战:
根据MemTable的ID号来确保主从节点中线程写入顺序一致
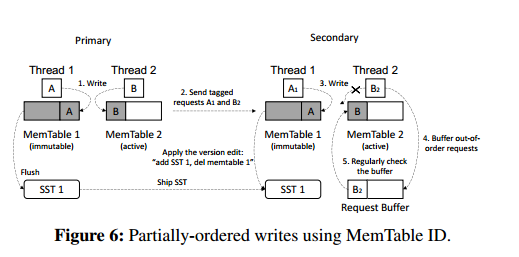
由于请求缓冲,在辅助节点上应用的更新可能滞后于主节点,所以辅助节点中的相同MemTable ID可能比主节点中的条目少。
主节点用序列号标记版本编辑以指示它们的顺序,次节点维护一个计数器和一个版本编辑缓冲区,每次辅助服务器应用版本编辑时,计数器都会递增。辅助节点在应用编辑之前检查两个条件:1)序列号是否等于计数器,2)其输入是否准备好。后者仅针对刷新作业进行检查,因为如果压缩通过了步骤1(即,先前的刷新或压缩作业已经完成),则压缩的输入总是就绪的。只有当MemTable变得不可变(满)时,它才是就绪的。如果这两个条件中的任何一个失败,版本编辑将缓存在缓冲区中,由所有线程定期检查。
5、总结
本文探索了如何将NVMe用于常见的数据库备份中,使用NVMe-oF进行复制的主要挑战是,目标节点可能需要在复制过程中并行读取数据,从而在文件系统和应用程序级别引入不一致性。本文陈述了如何在复制的基于LSM树的键值存储系统RubbleDB的上下文中解决这种不一致性,该系统使用两种主要机制:文件预分配和应用程序数据结构同步。