Enhancing and Exploiting Contiguity for Fast Memory Virtualization
本文研究了在虚拟机场景下的内存地址转换的开销问题
背景和问题:
随着计算机内存容量的增加,有限大小的TLB缓存会更频繁地发生miss,一旦TLB miss,就需要通过MMU硬件去内存访问多级页表,这会带来很高的延迟。 而在虚拟化场景下,需要两层地址转换,导致内存地址转换开销高达本地执行的6倍。 图1是在虚拟化场景下的地址转换示意图,客机操作系统的虚拟内存地址要通过客机操作系统的页表转换成客机物理地址,然后再通过hypervisor的页表转换成主机的物理地址。
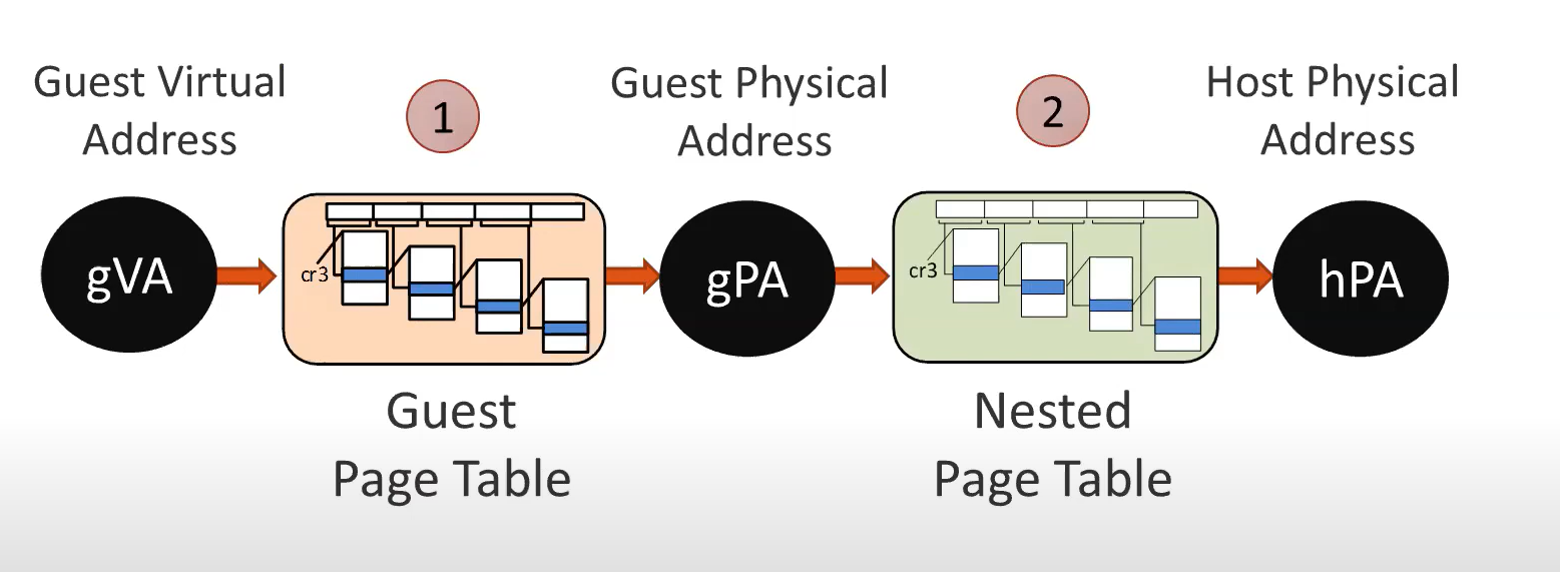 图 1 虚拟化场景下的内存地址转换
图 1 虚拟化场景下的内存地址转换
每当TLB miss时,需要查询页表,获取物理地址。这一问题在虚拟化场景中更为严重。 以图2为例,要查询每一级客机操作系统的页表,都需要先去主机页表进行一次页表遍历,获取那一级客机页表的起始地址,然后用gVA找到相应的条目,这样算下来,对于一共需要访问24次内存。
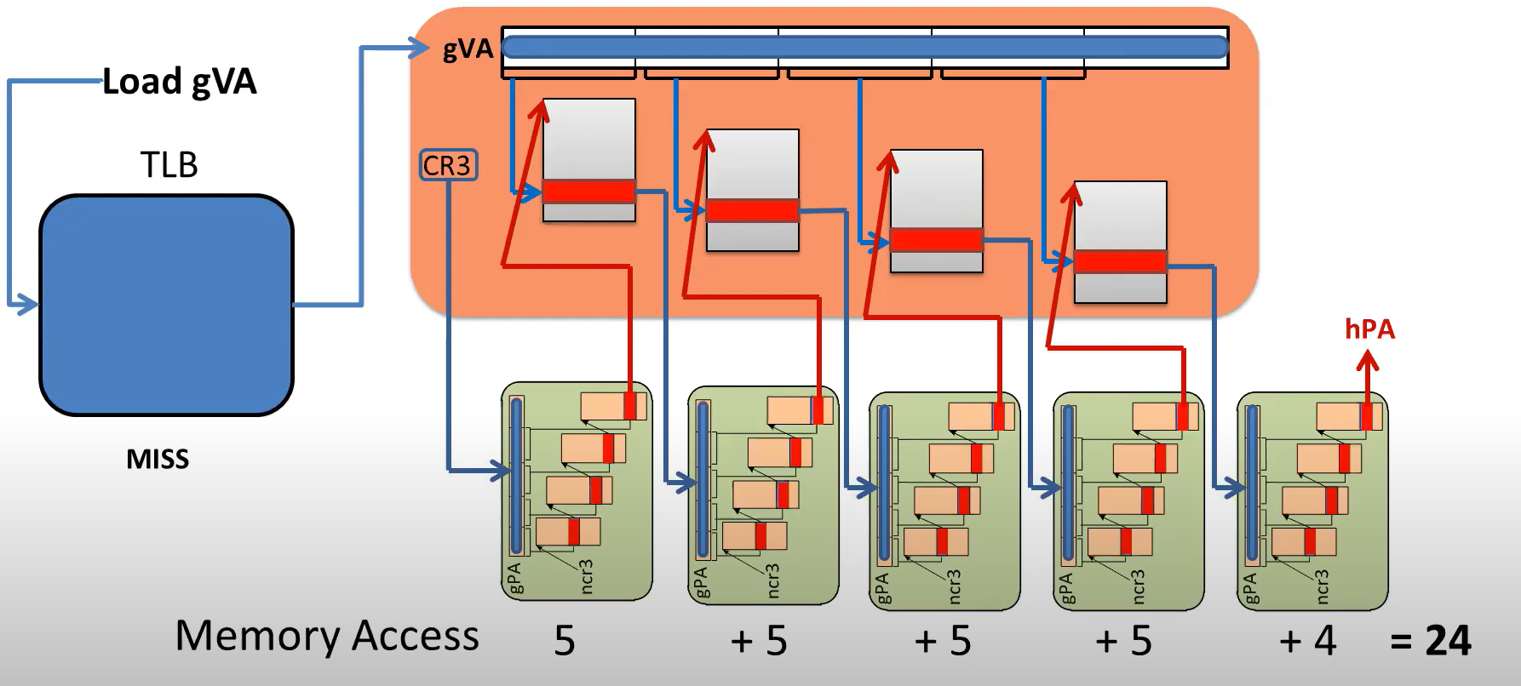 图 2 虚拟化场景下的页表遍历
图 2 虚拟化场景下的页表遍历
本文旨在降低虚拟化场景下的内存地址转换开销。
相关工作:
本文比较了最新的大页映射研究(软件),如图表1所示 Direct segment使用分段技术,将一个主要的VMA映射到一段连续的物理区域,并禁用这个VMA的paging机制。问题在于,这一段物理内存在应用被终止前不允许被回收 Eager paging采用提前分配内存的方式,但是会导致内存膨胀并且会因内存碎片化而无法生成大尺寸的物理页 translation ranger利用后台守护进程定期扫描进程的VMA,通过迁移物理页来生成连续的物理大页。他的问题在于会推迟一个应用生成大页,并且页迁移同样会给内存访问增加延迟以及触发TLB shootdown。
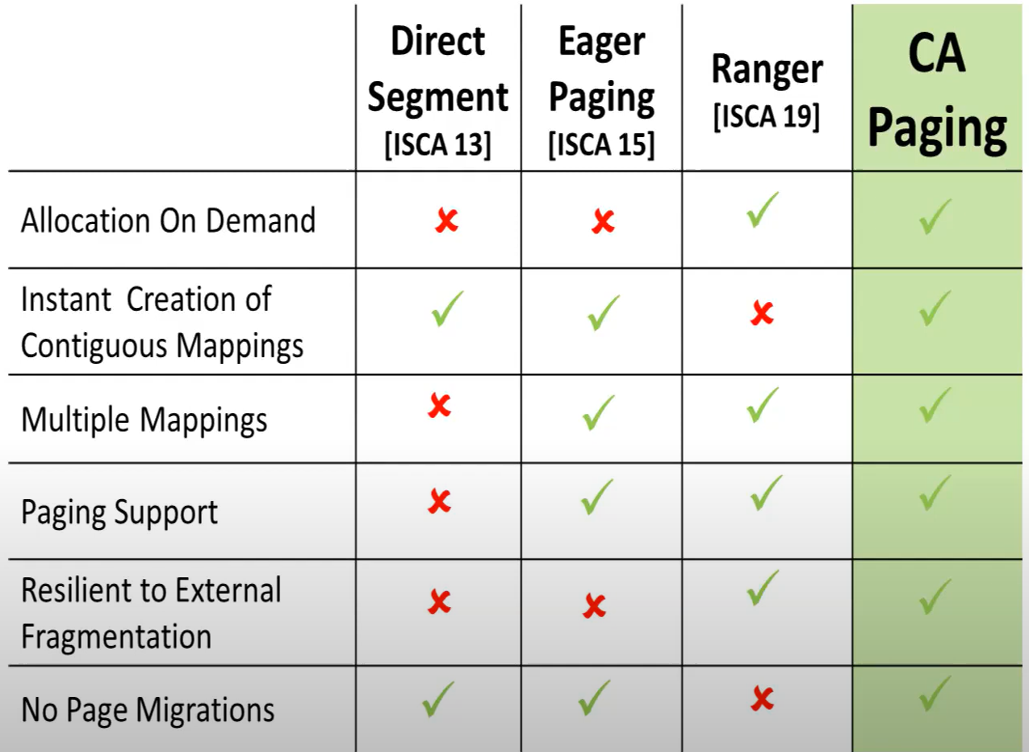 表 1 软件机制相关工作
表 1 软件机制相关工作
硬件设计方面,现有设计在虚拟化场景下变得低效或者成本过高 direct segment将boundary存放在特定寄存器中,并且没有对齐限制,但是不支持多种映射粒度 RMM设计过于复杂,每个处理器需要一个range TLB,每个进程需要一个range table,还需要硬件range table walker。 TLB coalescing将连续页映射合并成一个大页映射并存放在TLB中,合并的映射条目存在对齐的限制。 以上机制在虚拟化场景中,需要为每个虚拟机和客机操作系统分别维护多个虚拟的硬件结构和元数据,开销很大
表2展示了RMM和TLB coalescing两种设计要覆盖5种负载99%的进程空间所需要的页数,通过对比左右两种大页映射机制, 可以看到CA paging有效减少了页数。同时可以看到TLB coalesing设计使用的页数要远高于RMM,这是因为映射存在对齐限制而无法有效合并大页,
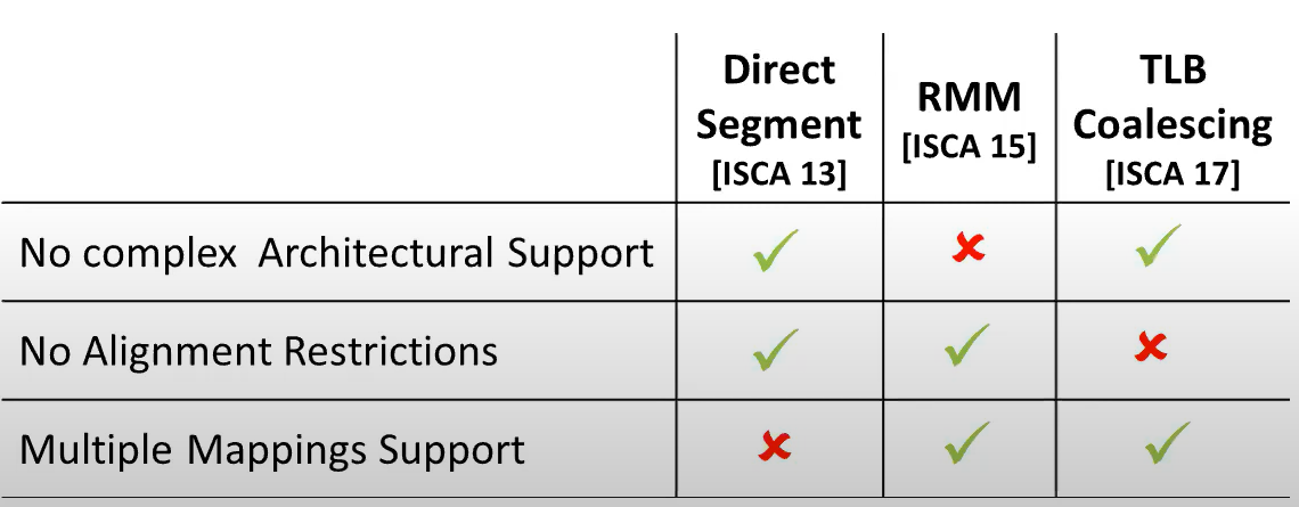 表 2 硬件机制相关工作
表 2 硬件机制相关工作
设计:
设计目标: 解决现有大页映射的软硬件设计存在的问题,即避免内存膨胀,保留按需分配的灵活性,不受地址对齐的限制,在page fault时立即分配大页并避免在分配之后物理页迁移的开销,以及通过避免追踪物理和虚拟区域的边界减小硬件设计的复杂度。
- CA paging
依赖于现有的demand paging,防止因预分配导致的存膨胀,但不是随机的分配物理页,而是分配连续的物理区域。
CA paging共使用两种元数据:Offset+contiguity map: 如左图所示,一个VMA可能有多个大页映射,offset记录了一个大页映射中物理起始地址与虚拟起始地址的差值
Contiguity map基于现有buddy allocator的链表,记录了系统内存当前的所有空闲连续物理内存段,称为cluster,这个map记录了每个cluster的起始物理地址和大小,并且这些cluster不受对齐和大小的限制。为了加速map的搜索效率,在属于一个cluster的4KB物理页的page结构体中记录了指向这个cluster的指针。
如图4所示, 当一个VMA被第一次访问时,发生第一次page fault,为了避免随机分配物理内存段导致的碎片化问题,CA paging用VMA的大小作为key查询contiguity map, 找到最合适的的块分配给这个VMA。当同一个VMA在下次发生fault时,就可以准确定位到目标物理页,再通过检查目标物理页的反向映射信息判断其是否空闲,若空闲,则这段大页映射的尺寸可以增加。 CA paing并不会为整个VMA分配物理内存,而是仅为每次fault的区域分配相应的内存。为了避免同一个物理内存区域被争用,采用next-fit策略,即在为下一个请求分配物理内存的时候,会最后考虑使用上一次使用过的区域。如果发现目标物理页被占用,如果是这个page fault是大尺寸VMA触发的,那么CA paging会为剩余fault区域重新执行大页分配,并记录新的offset。 此外,为了防止碎片化,会进行类似于buddy allocator一样的合并。最后,在虚拟化场景中,本文为两个维度(主、客机操作系统)的地址转换分别实现了一套独立的CA paging机制。
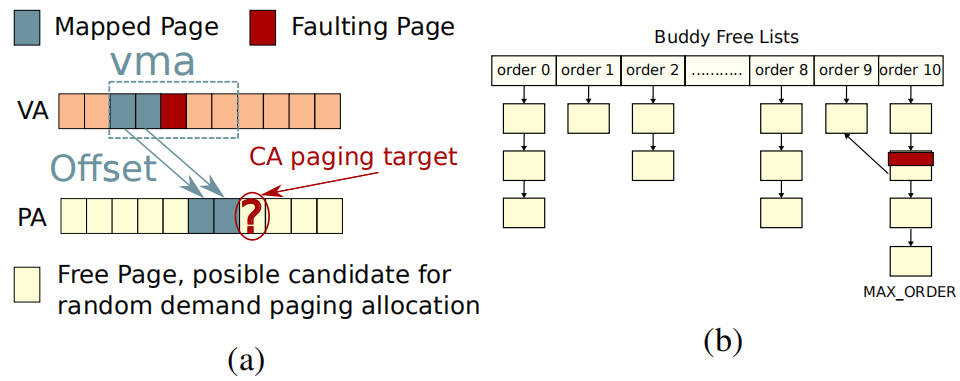 图 3 CA paging数据结构
图 3 CA paging数据结构
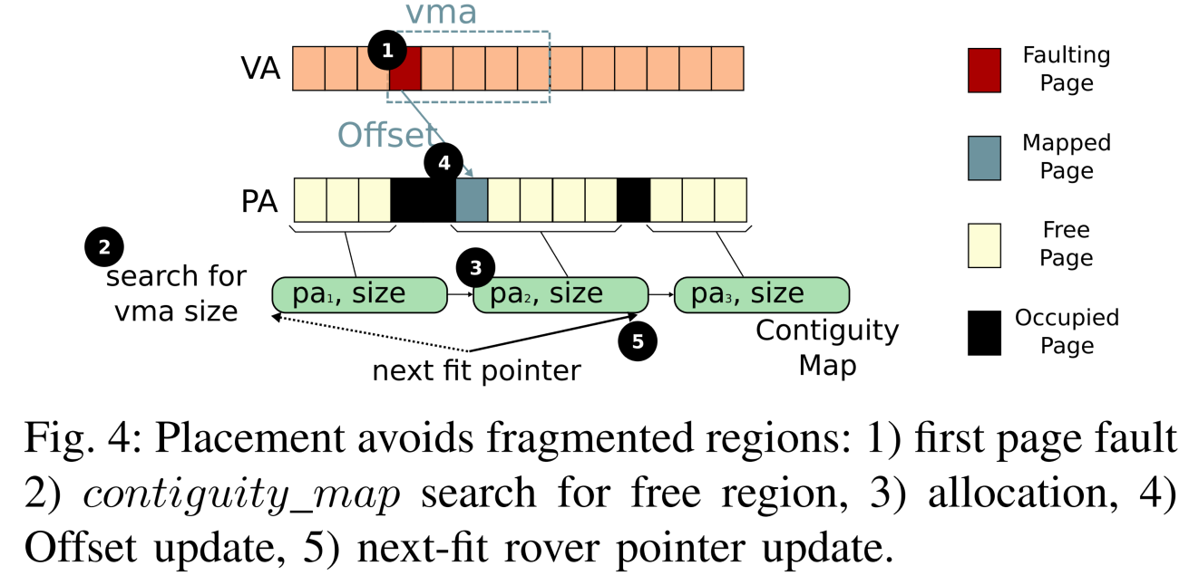 图 4 CA paging执行逻辑
图 4 CA paging执行逻辑
- SpOT
为了加速在虚拟化场景下的地址转换,本文提出了硬件设计SpOT。
本文发现现有硬件设计(RMM,hybrid coalescing)在虚拟化场景下元数据开销高或者性能差是因为需要对页映射的虚拟和物理边界需要进行记录或存在地址对齐的限制。 因此SpOT仅仅追踪二位地址映射的offset,并假设指令的访问具有局部性,即大部分的TLB miss仅仅是由某几个指令导致的,即假设某内段存的访问与某几个指令直接相关。
SpOT的核心是一个预测表,记录了对应于PC的二维映射的offset和访问许可,通过程序计数器PC来索引和比较预测是否命中。 如图5所示, 当执行某个指令第一次发生TLB miss时,程序需要stall,直到查询完page table,SPOT会记录这个PC和发生fault的offset 当下次再次执行同一条指令的时候,SPOT直接用offset预测出要访问的物理地址,然后执行操作,后台会并行地查询页表,并检查预测的正确性,如果发现结果相同,意味着预测命中,从而隐藏了page walk的开销。 如果预测命中,那么就相当于隐藏了页表查询的开销,如果预测失败,就需要用正确的物理地址重新执行这条指令。
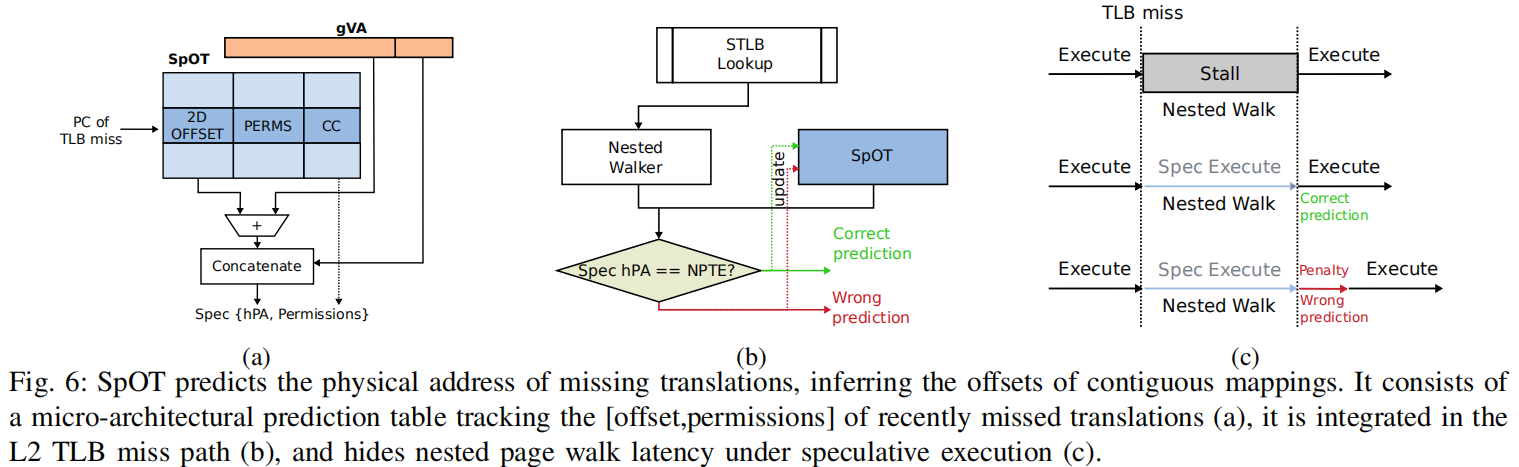 图 5 SpOT执行逻辑
图 5 SpOT执行逻辑
实验:
基于Linux kernel 4.19修改, 用QEMU/KVM 2.1.2实现虚拟化环境,并用badgetrap来仿真硬件设计