Batch-Aware Unified Memory Management in GPUs for Irregular Workloads [Paper] [Video]
统一内存(Unified Memory)
统一内存利用虚拟内存对多个地址空间(包括硬盘、GPU缓存等)进行统一编址,然后通过缺页中断实现透明的页迁移。
问题分析
统一内存降低了编程难度,程序开发人员不需要进行显式的数据迁移,然而数据迁移仅仅被“隐藏”而不是消失了。除了迁移本身的开销,统一内存还增加了中断处理和虚拟内存管理的开销。这对内存密集型负载,如GPU负载,是不友好的。所以GPU运行时通过合并多个缺页中断来降低相应开销。
中断合并
什么情况下缺页中断会比较多呢?答案是,当短时间内需要访问比较大范围数据的时候,即不规律负载(Irregular Workloads),通常为图的遍历!当使用的GPU核数增多时,不规律负载访问的数据范围远高于常规负载:
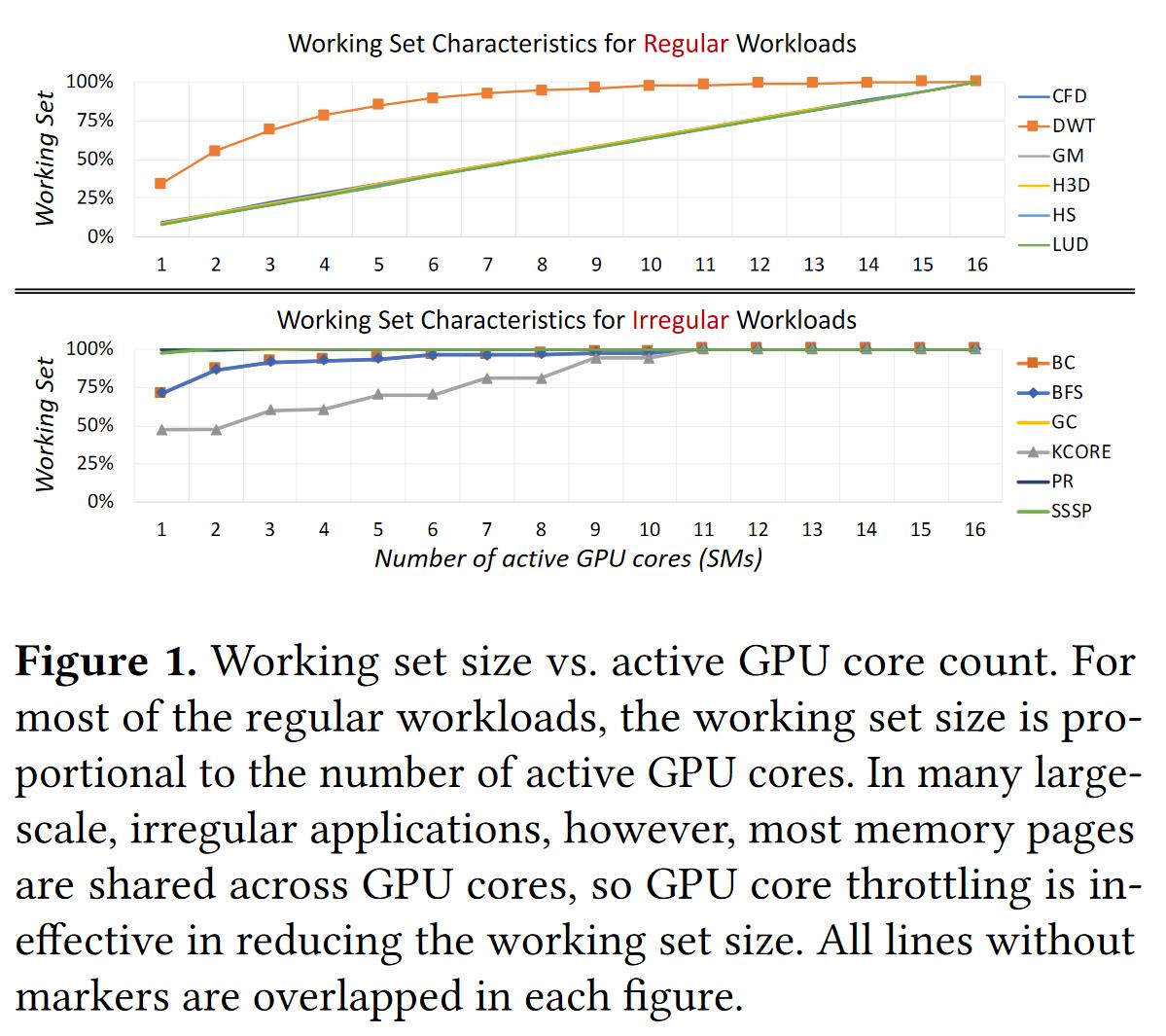
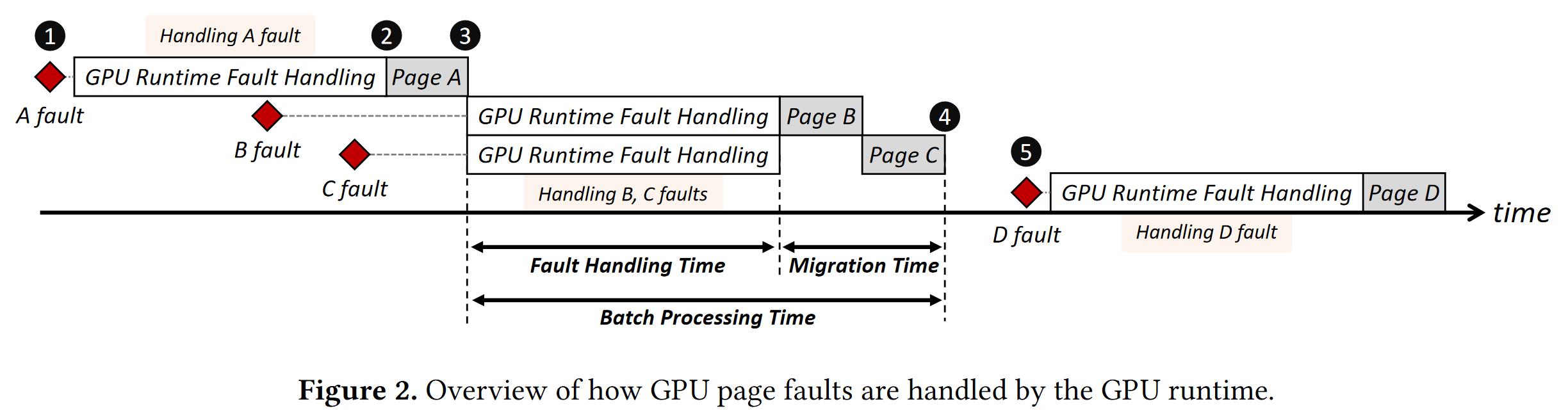
访问的数据范围大,缓存命中率于是就会下降,中断请求紧接着就会增多。那么采用如下图所示的中断合并会带来什么变化呢?
我们会发现平均每个缺页中断的处理时间随着批处理大小的增大而近似于指数减少:
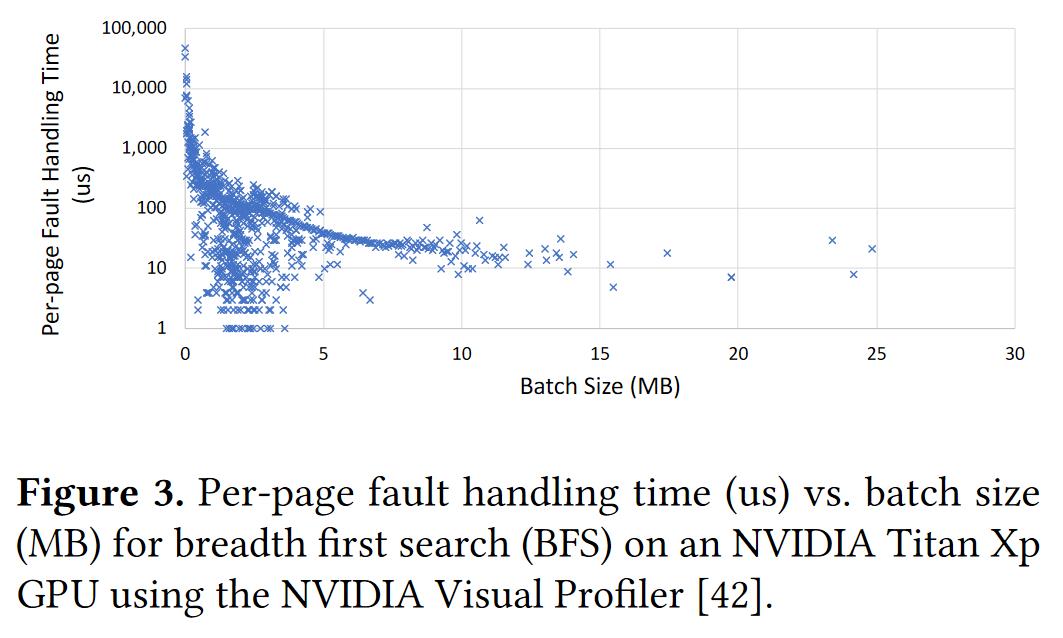
虽然合并中断可以有效降低单个缺页中断的处理时间。但是增加中断请求数量,增大批处理大小并不容易。 简单的做法之一,可以包装一些接口提前访问数据从而提前发起中断,但是并不一定高效。 第二种做法是增加线程数量,但是线程本身有比较大的开销,占用内存资源,增加线程切换。
内存替换
除了利用批处理减少中断的平均处理时间,另一个办法就是减少中断本身的时间。通过下图可以发现,页替换过程中的逐出占用较大时间,然而逐出并不是处理缺页的关键过程。
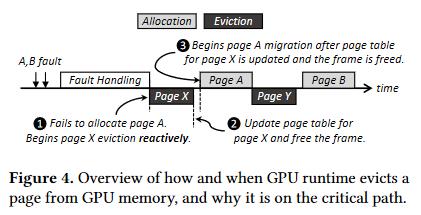
解决方法
根据以上发现,这篇论文通过两个优化提高性能。
虚拟线程
通过增加虚拟线程,而不是真实线程,进一步提高批处理大小。
异步逐出
现代的DMA传输支持全双工的双向通信(bidirectional),也就是读和写可以同时传输数据(UFS/NVMe均支持)。但是操作系统的页替换只能顺序执行,并不能很好利用DMA双向通信机制。
通过异步的进行逐出,降低单次页替换的开销,从而让逐出可以与其它操作并发执行。