0sim: Preparing System Software for a World with Terabyte-scale Memories
最近内存技术的进步意味着商品机器可能很快就会有TB级的内存,然而,这种机器目前仍然很昂贵且少见。因此,很少有研究人员能够针对可伸缩性问题进行调试和原型修复,或者探索由TB级内存引起的新系统行为。
为了对这种机器能够快速、早期的原型化并探索其系统软件的行为,本文设计了0sim模拟器并将其开源。0sim使用虚拟化来模拟在普通机器上执行的大规模工作负载。我们的关键观察是,无论输入是什么,许多工作负载都遵循相同的控制流。我们称这种工作负载为数据无关的。0sim利用数据无关性,通过内存压缩使大型模拟变得可行和快速。
0sim对于许多任务来说足够精确,并且可以模拟一个比主机大20-30倍的客户系统,对于我们观察到的工作负载,它的速度会有8-100倍的减缓(可压缩的工作负载运行得更快)。例如,我们可以在31GB机器上模拟1TB机器,在160GB机器上模拟4TB机器。我们通过实例来说明0sim的实用性。例如,我们发现对于混合工作负载,尽管有几十GB的空闲内存,Linux内核仍然会创建不可修复的碎片,并且我们可以使用0sim来调试运行在大内存上的memcached的意外失败。
0. 写在前面
0.1 Simulator和Emulator的区别
相同之处
Simulator和Emulator两者都可以在灵活的软件定义网络的环境中执行软件测试。而且这种方式比在真机中测试更快速更简单。真机测试往往在软件发布以用于生产力之前。
不同之处
Simulator用于创建包含了应用程序真实生产环境中的变量和配置的模拟环境,但是不会尝试仿真生产环境中真实的硬件,因为Simulator只是创建软件环境,这种环境可以通过高级编程语言实现。
Emulator会尝试模拟生产环境种所有的硬件功能和软件功能,可能需要使用汇编语言来编写。
可以认为Emulator是Simualtor和真实机器之间的一层。Simulator只是模拟了可以用软件定义或配置的功能环境,而Emulator模拟了软硬件功能。
1. 大内存系统的问题
随着内存容量呈指数级增长,过去严格限制最大内存大小的设计(例如,IBM的System/360的架构限制为28MB)面临着巨大的困难。随着技术的进步,存储器的密度大大增加,成本大大降低,这种增长趋势将继续下去。最近,英特尔的3D Xpoint内存支持高达6TB的双插槽机器。因此,多TB的系统可能会变得普遍,为未来拥有几十到几百TB内存的系统铺平道路。
虽然在今天可以容忍,但是当内存增加10-100倍时,许多常见操作系统算法的线性计算和空间开销可能是不可接受的。其他系统软件,如公共语言运行库和垃圾收集器也需要重新设计,以便在多TB内存系统上有效运行。在Linux中,许多可伸缩性问题对于小内存是可以容忍的,但在更大的规模下则是不能接受的,例如:
- 对于4TB的内存,Linux在启动时需要超过30秒来初始化页面元数据,这降低了重新启动时的可用性。
- 在大型系统上,内核元数据增长到多个GB。在异构系统上,元数据可能会占满较小的快速内存。
- 线性复杂度的内存管理算法(如内存回收和碎片整理)在内存扩展10倍时可能会导致显著的性能开销。
- 为小内存构建的内存管理策略(例如允许固定百分比的缓存文件内容是脏的)在大内存中表现很差,当这个小百分比由几百GB组成时。
但是,探索具有巨大内存的系统行为、再现可伸缩性问题和原型解决方案需要巨大的成本。4TB实例的云服务每小时成本超过25美元。较大的实例需要三年的合同,费用超过780000美元。
计算效率低下
任何执行时间随内存量线性增加的操作都可能成为瓶颈。例如,页帧回收算法、大页压缩、页重复数据删除、内存分配和脏/引用位抽样都是对每页元数据进行操作的。如果内核试图透明地将一系列页面升级为一个巨大的页面,那么运行巨大的页面压缩可能会导致应用程序中出现不可预知的延迟峰值和长尾延迟。
内存占用
在某些情况下,任何与主存大小成比例的内存使用都可能占用太多空间。例如,一台具有少量DRAM和TB级非易失性内存的机器可能会发现它的所有DRAM都被页表和非易失性内存的内存管理元数据所消耗。
大内存策略
针对小内存的有效内存管理策略在大内存时可能表现不佳。例如,在Linux内核中,一旦脏页超过了一定的内存百分比,就会将它们刷新到存储中,但是在大型机器上,这会导致长时间的暂停,因为会有GB级的数据被刷新。
2. 0sim设计
0sim允许在具有巨大物理内存的机器上评估系统软件。0sim不是一个架构模拟器,相反,它有以下目标:
- 运行在廉价的硬件上。
- 对模拟软件要求最小的更改。
- 保持性能趋势,而不是精确的性能。
- 运行足够快以模拟长时间运行的工作负载。
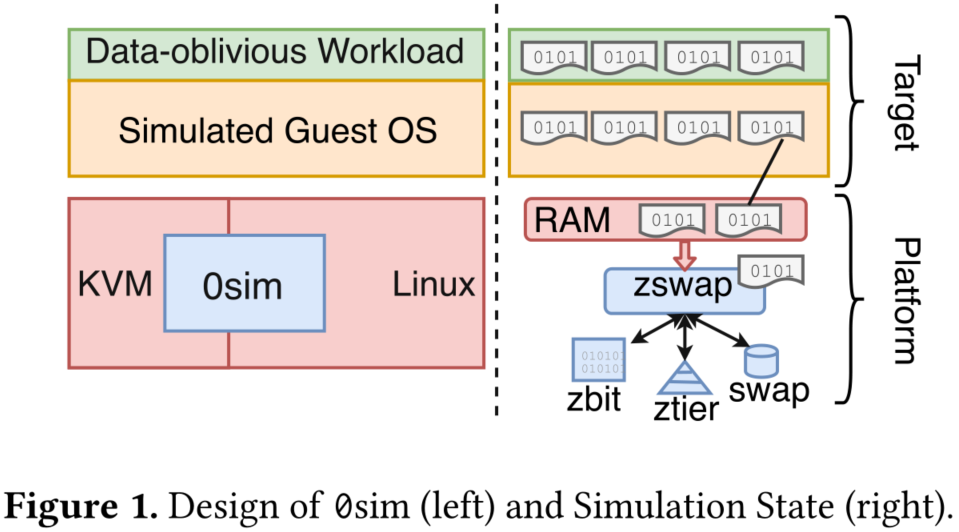
图左显示了0sim架构概述。0sim引导一个虚拟机(VM)作为目标,使用的物理内存比主机或平台上可用的物理内存大几个数量级,同时保持合理的模拟速度。0sim是作为在平台上运行的经过修改的内核和管理程序实现的,但不需要进行任何目标的更改。任何未修改的目标操作系统和各种各样的工作负载都可以通过在目标中执行它们来模拟(例如,通过SSH)。X86 rdtsc指令可以在目标中用来读取硬件时间戳计数器(TSC),以进行模拟时间测量。
0sim面临的主要挑战是:
- 模拟巨大的内存
- 突破物理地址大小限制
- 保存时间度量
分别所使用的的解决方法:
- 使用数据无关的负载
- 使用0sim的影子页表替代CPU转换
- 虚拟化硬件时间戳计数器(TSC)
2.1 数据无关性
我们的关键观察是,无论输入是什么,许多工作负载都遵循相同的控制流。我们称这种工作负载为数据无关的。例如,内存中的memcached键值存储并没有根据键值对中的值而表现出不同的行为——反而只有键。另一个例子是固定的计算,如矩阵乘法;我们可以用稀疏或已知的矩阵提供矩阵工作负载。
Figure 1(右)描述了0sim中目标状态的管理。为数据无关的工作负载提供预先确定的数据集,使其能够在不改变其行为的情况下进行内存压缩。0sim能够识别带有预先确定内容的页面(本次识别的是零页面),并将它们压缩到1位,存储在一个名为zbit的位图中。与预先确定的内容不匹配的页面可以被压缩并存储在名为ztier的高效内存池中。这允许0sim运行大型工作负载,同时在一个更普通的平台机器上保持模拟状态。此外,由于大部分模拟状态都保存在内存中,所以与必须将所有状态写入交换设备相比,zbit能够更快地模拟。例如,在我们的工作站上,将4KB写入SSD大约需要24个µs,而LZO压缩只需要4个µs。
2.2 影子页表
现有的商品系统可能不支持我们希望研究的内存大小,这种硬件限制阻止了运行大内存工作负载的研究。0sim使用阴影页表克服了地址大小的限制:由管理程序(而不是硬件)将目标物理地址转换为适当宽度的平台物理地址。
0sim使用阴影页表将目标地址空间的大小与平台处理器中的物理地址位的数量解耦。系统管理程序读取来宾内核的页表并构造影子页表,硬件使用这些影子页表将来宾虚拟地址转换为主机物理地址。硬件永远看不到客户物理地址。
2.3 时间虚拟化
硬件模拟器(如gem5),经常使用模拟器生成的离散事件来模拟时间的流逝。然而这是非常缓慢的,与本机执行相比会导致数量级的减缓。这样的慢速度使得在中长时间尺度上研究大内存系统的行为变得不切实际。相反,0sim在平台上使用硬件时间戳计数器(TSCs)来测量时间的流逝。
每个物理核心都有一个独立的硬件TSC,可以连续运行。我们为目标创建一个虚拟硬件TSC,只有当目标在运行时,系统管理程序才能增加这个TSC。0sim虚拟化rdtsc x86指令,该指令返回一个周期级硬件时间戳计数器(TSC)。每个物理核心都有一个独立的TSC, Linux内核在引导时同步它们。大多数Intel处理器都能够虚拟化TSC。
3. 验证
本节用于演示0sim足够精确,可以用于再现可伸缩性问题、原型化解决方案和探索系统行为。
3.1 实验设置
图中,wk-old是一台6年历史的工作站机器,有31GB的DRAM。wk-new是一台有4年历史的工作站机器,64GB的DRAM。这两台机器最初购买时的价格都在1000-2000美元左右。server是一个具有160GB DRAM的服务器类机器。这些机器的成本都比一个巨大的内存机器或长期租用云实例的成本低几个数量级。
我们的baseline是直接执行(而不是模拟)AWS 1e.32xlarge实例,内存3904GB,每小时价格26.818美元。
3.2 准确性
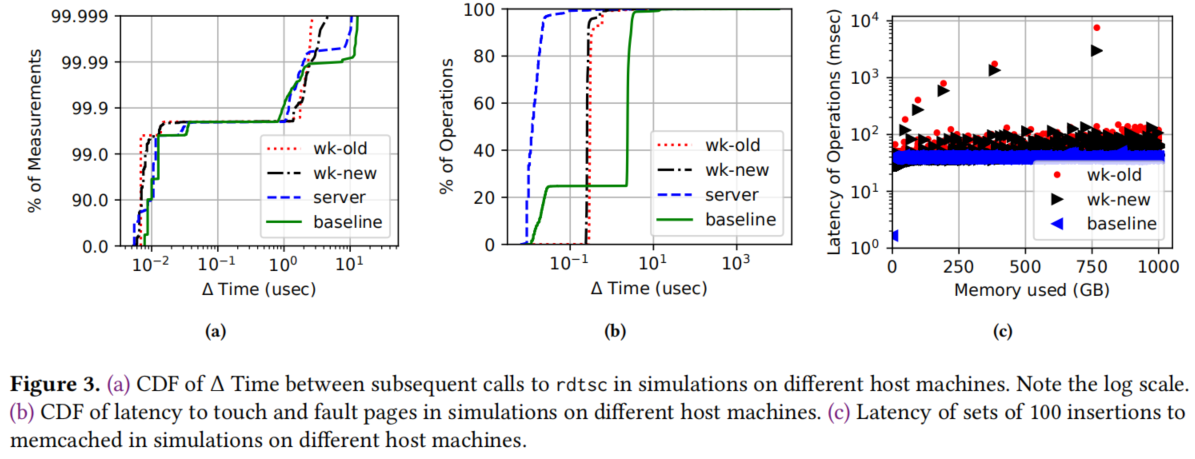
分为单核准确性(图3)和多核准确性(图4)。
图3a显示了时间戳差异的CDF;图3b显示页面分配的结果时间的CDF;图3c显示100个插入操作的延迟,上面的点体现了resize操作的延迟。
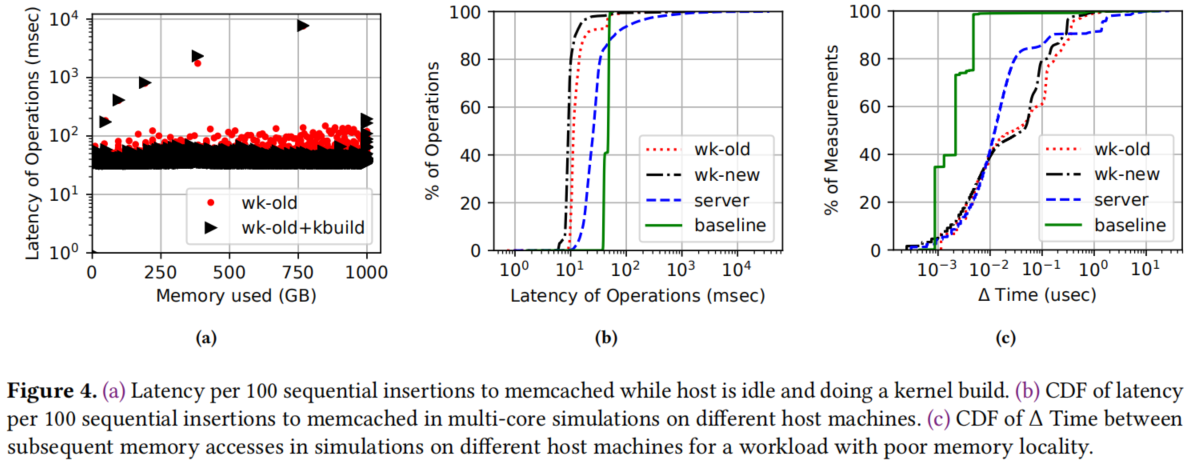
多核不是很准确,但是保留了趋势。
3.3 数据无关性
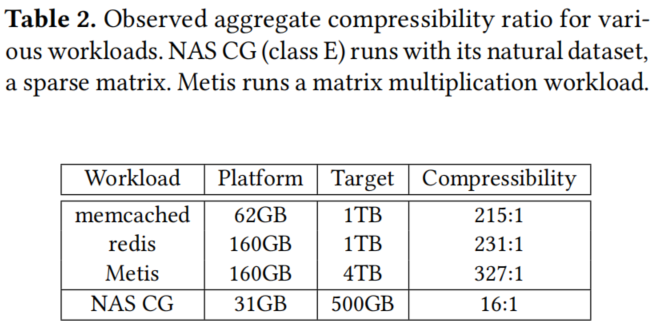
表2报告了我们实验中几个示例工作负载的聚合压缩率,它是内核试图插入到Zswap的所有页面的平均压缩率(这与平台内存与目标内存的比率不同)。
3.4 模拟速度
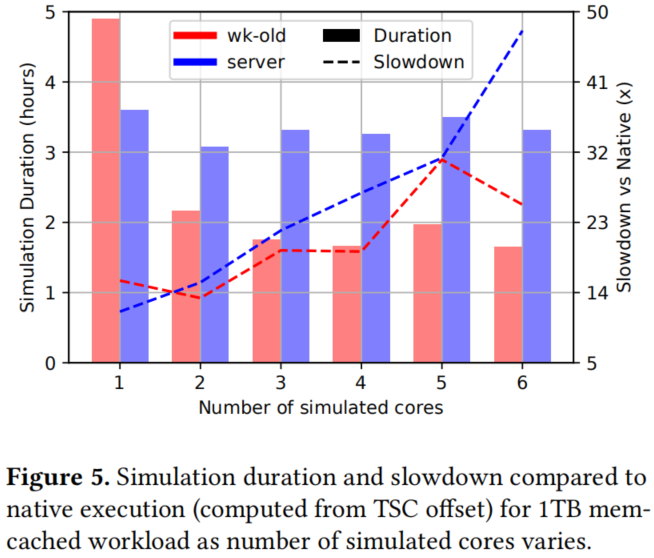
模拟速度在很大程度上取决于工作负载、平台和模拟核的数量。图5显示了随着模拟核数量的增加,1TB memcached工作负载的模拟速度。在我们的实验中,与本地多核执行相比,我们通常观察到8倍到100倍的速度放缓。作为参考,这相当于在20世纪90年代末或21世纪初的处理器上运行工作负载。架构模拟通常会导致10000倍或更糟的速度减慢(如Gem5)。我们发现,由于I/O虚拟化,高I/O工作负载会变慢。
4. 案例学习
0sim对于原型和测试以及研究和探索都很有用。
4.1 用于开发
与0sim工作负载交互的能力被证明是非常宝贵的。在运行实验时,memcached在从8TB的数据中只插入了2TB的数据后,返回了一个意外的内存不足错误。为了理解为什么memcached行为不正常,我们在正在运行的memcached实例上启动了一个交互式(尽管很慢)调试会话。我们发现memcached的分配模式在glibc的malloc实现中引发了病态的情况,导致大量对mmap的调用。这导致分配失败,因为系统参数限制了每个进程的内存区域。增加限制可以解决这个问题。
这个事件说明0sim对于查找、重现、调试和验证只发生在大内存系统上的错误的解决方案非常有用。memcached的一个主要开发人员不确定这个问题,因为他们没有尝试过在大于1.5TB的系统上使用memcached。我们希望0sim能让系统社区更好地为大内存系统的更广泛可用性做好准备。
4.2 用于探索
在处理大内存工作负载中碎片的影响方面的工作很少。0sim非常适合研究这种工作负载及其系统级影响。
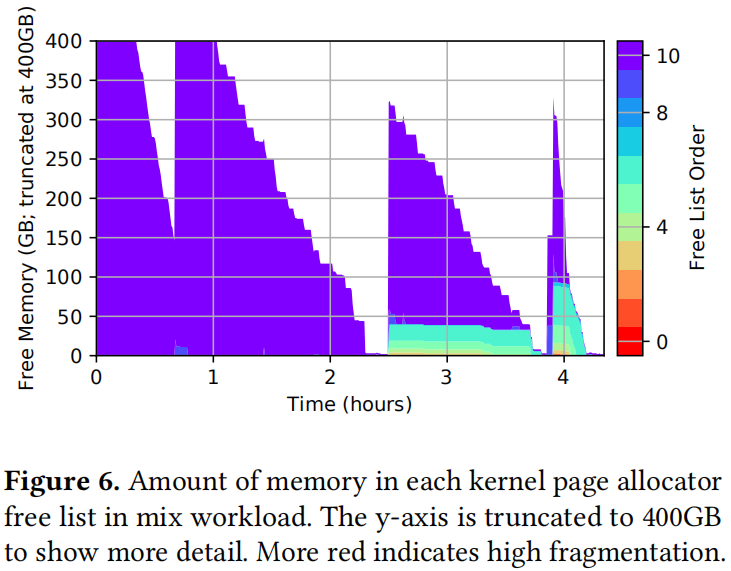
单独运行时,Redis不会受到碎片化的影响,但在存在其他工作负载的情况下,它会受到影响。图6显示了整个混合工作负载中每个伙伴列表中的可用内存量。更多的紫色(顶部)表示更大的连续空闲物理内存区域,而更多的红色(底部)表示物理内存高度碎片化。每一次空闲内存运行得较低,对于工作负载的后续部分,碎片就会降低:在2.5小时之前,几乎没有碎片,但在2.5小时之后,几乎有40GB的空闲内存处于8级或更低的水平,在4.2小时之后,几乎有100GB处于8级或更低的水平。请注意,分配一个大页面需要9或更高的顺序。经过进一步的检查,我们可以看到,虽然大多数区域是连续的,但许多独立的基页分散在物理内存中。这些页面代表某种“潜在的”碎片,尽管释放和合并了几百GB的内存,这些碎片仍然存在。这表明任何真正的防碎片解决方案都必须处理这种“潜在的”碎片。
更多案例可参见论文原文。