论文来源:
本文来自舒继武和陆游游老师团队。
背景:
键值存储中的小型访问与PM的持久性粒度不匹配,导致PM带宽未得到充分利用(即写放大问题)。而我们可以通过将访问进行批处理,将聚集起来的小型访问一次性下刷,利用PM中的XPBuffer进行写合并操作,从而降低写放大问题,充分利用PM带宽。
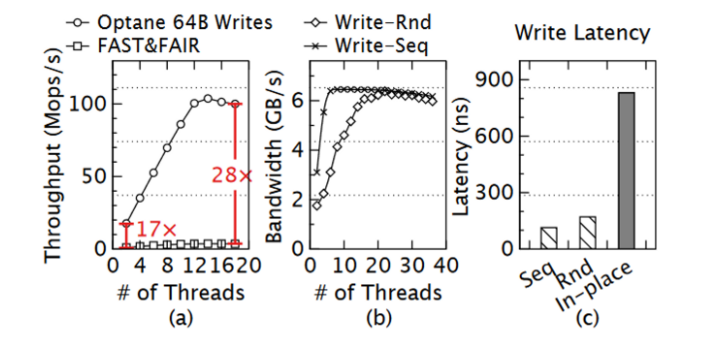
如下图所示。(a)中FAST&FAIR需要为每个操作生成多个小规模写入,不必要地浪费了PM带宽,所以吞吐量比PM带宽小了一个数量级。(b)中展示了在高并发情况下,顺序访问模式和随机访问模式的带宽相似。(c)中作者发现当写入操作被刷新(通过 clwb)时,对同一缓存行的后续写入和刷新将被阻塞近 800 ns。总之,对于那些采用 “就地 “更新方式的存储系统来说,这种行为是个大问题,尤其是在运行倾斜工作负载上时。
设计:
要利用PM中的XPBuffer,意味着聚集起来的小型访问必须下刷到一个连续地址,解决上述问题的经典方法是使用日志结构的KV存储,这样所有更新都可以简单地附加到日志中。并且,通过对来自客户端的多个请求进行批处理并同时执行更新,写入开销(mfence操作)可在多个请求中分摊。
要解决上述背景问题,存在两个挑战。
1)PM 具有更精细的访问粒度(64 B 刷新大小和 256 B 内部块大小),这限制了可以一起刷新的更新数量。并且因为每个日志条目都需要封装额外的元数据,这种放大使得更难从批处理中受益。
2)批处理往往带来更高的延迟,怎么降低这种延迟,本质上来说是增加批处理机会。
作者提出下面两个解决办法:
1.紧凑型日志
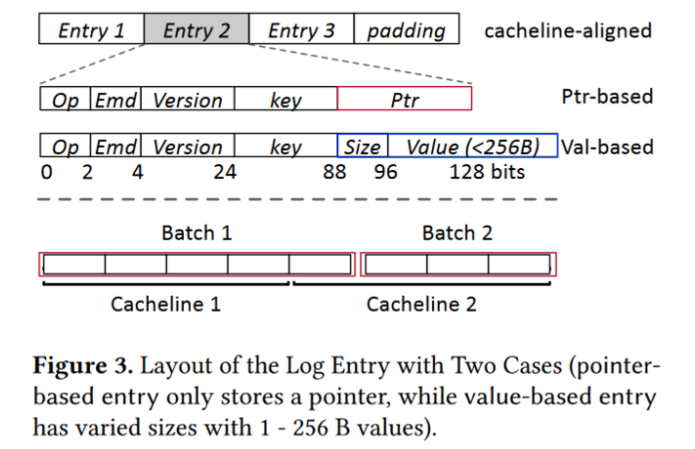
FlatStore 只在log条目中存储索引元数据和小型 KV。大型 KV 使用 NVM 分配器单独存储,因为它们无法从日志中的批处理中受益。当value的大小为1-256B时,直接将其存储到日志条目。对于大value,只存其地址指针。
2.垂直管道批处理
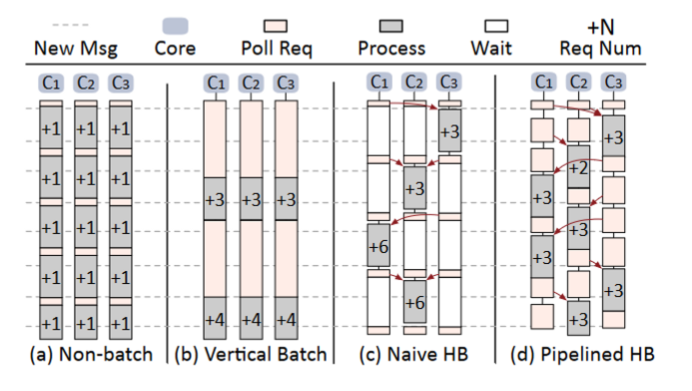
即:允许一个核心在创建批处理时,从其他核窃取日志条目,从而更快地凑齐这个批处理,以降低延迟。
见下图(d)所示,采用流水线式的批处理。批处理的执行有一个全局锁,获得该全局锁的内核可以进行批处理的执行,只在窃取日志阶段持有该锁,下刷阶段前就释放,所以持久化的时间被提除出去,形成流水线。由于大量的CPU内核竞争一个全局锁会造成巨大同步开销,所以可以将服务器的内核分为若干组。
实现:
1)由于日志条目保存在PM上,所以只需要在DRAM上维护一个易失性索引,如下图。作者实现了两种索引方案,一种是基于hash表,一种是基于MassTree。每个cpu核维护自己的索引,但由于上述垂直管道批处理技术,即使是数据倾斜的负载也不会造成负载不均衡问题。
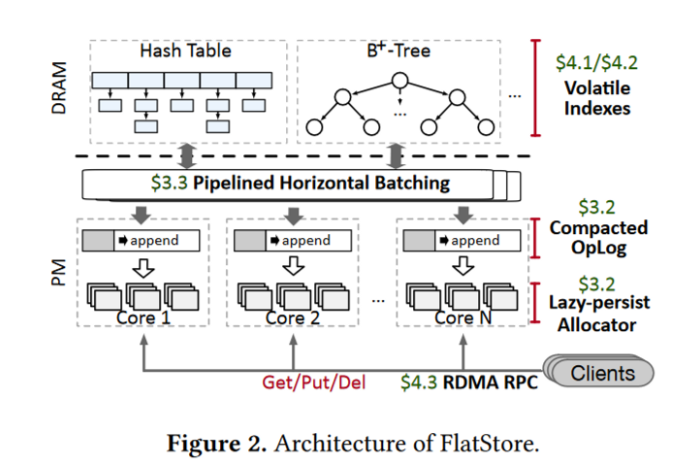
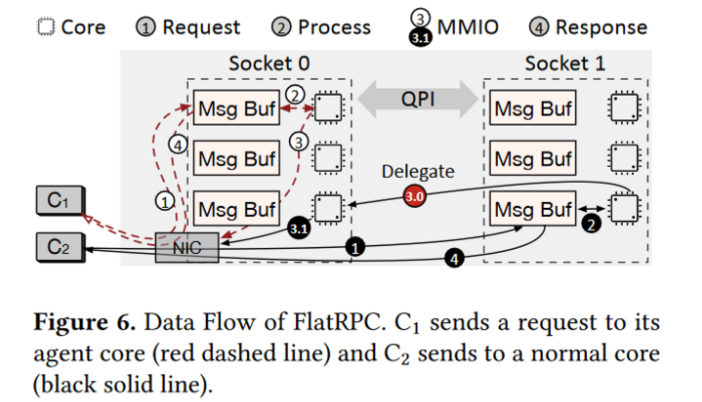
2)访问KVS的客户端直接发送请求到服务端的特定核心,每个核心预分配了一个msg buffer,客户端通过RDMA write直接将请求写入,每个服务端核心轮询该msg buffer以提取新信息进行处理。
但是,会存在一个可扩展性问题:
FlatStore 要求客户端可以向客户端指定 ID 的服务器核发送请求,这意味着每个服务器节点必须创建 Nt × Nc 的QP(其中 Nt 是每个服务器的核数,Nc 是每个服务器的核数)。
解决办法:
所有的回复都委托给特定的一个CPU核进行回复,所以只需要该CPU核维护Nc个QP。由于verbs是轻量级(几个字节),委托回复的成本并不大。
实验结果:
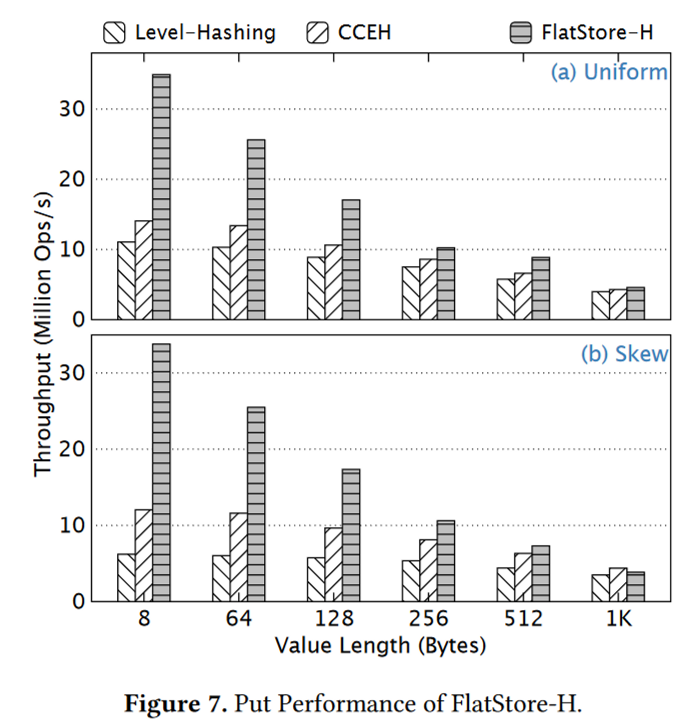
1)无论是在均匀负载还是在倾斜负载,FlatStore的吞吐量均比Level-Hashing和CCEH高,但随着kv的增大,三者的吞吐量相近,因为大kv主要受限于PM的带宽:即使日志批处理了,但value的写入操作占据大量带宽。
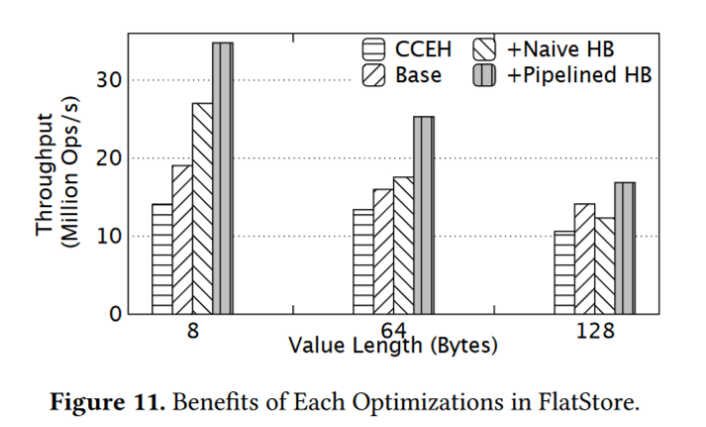
2)下图为本文所做优化结果的分析。base为不采用批处理,Naive HB为非流水线的垂直批处理,PipeLined HB为最终设计流水线垂直批处理。对于小 KV,Naive HB 显示出比 Base 更高的性能,但在128B,因为 Naive HB下刷时将推迟其他CPU核心的执行,此时下刷时间较长,造成性能更差。
流水线HB在所有情况下都带来了显着的好处,因为它1)将小尺寸的日志条目和小KV合并到更少的缓存行中,并大大减少了PM写入的数量; 2)提前释放锁,使得其他服务器核心能够并行执行下一批。
思考:
亮点:采用流水线式的批处理技术,不仅降低了批处理的延迟,更巧妙的解决了倾斜负载下的负载不均衡问题。
问题:
1)委托回复时,每个核心将自己的需要回复的verb command写到一个共享内存区域,这可能会带来竞争问题。
2)垂直流水线批处理时,仅仅在窃取日志时持有全局锁,由于持久化占据大部分时间,那么肯定会造成同步问题。上一个batch写入key = 2,还没下刷,下一个batch就来查询key=2了,从而读取不到正确数据。文中说了一下延迟相同key的操作的执行,在特定负载下是否会造成延迟增加。