论文来源
Replicating Persistent Memory Key-Value Stores with Efficient RDMA Abstraction (OSDI’23)。
本文来自舒继武和陆游游老师团队。
背景:
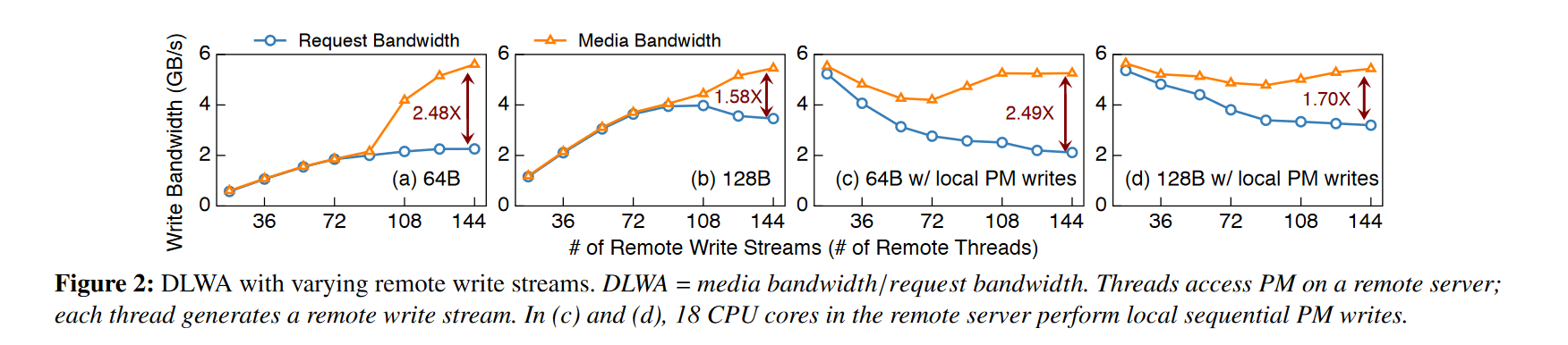
实际工作负载中普遍存在微小对象,这些复制写入量通常很小(~100B),直接写入的话会对PM(PM内部的写粒度为256B)造成很大的写放大。同时,在分布式KV系统进行主备复制时,由于每台主机存储了多个备份,会给PM带来大量的写入流,PM自带的写合并部件XPBuffer大小约为16KB,大量的写入流会使得XPBuffer难以发挥写合并功能,进一步加剧了写放大问题。如Figure 2所示,随着写入流增加,写放大问题越来越明显。
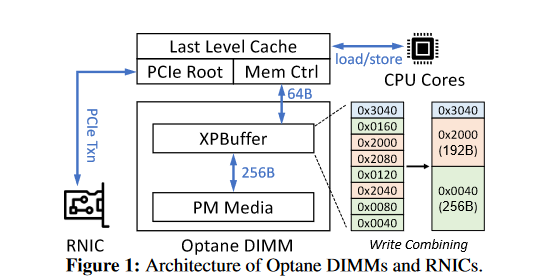
目的:
减轻高扇入小写(大量写入流+小写)带来的写放大问题,从而提高PM吞吐。
ROWAN的设计基于以下两个观察:
- RDMA SEND的控制路径是two-sided,但是数据路径是one-sided。即,接收方在将recv推入RQ时,需要接收方CPU参与,而在发送方发送数据到达接收方从而消耗recv时,是不需要接收方cpu参与的。
- RNIC按顺序使用receive buffer。可以保证命令的顺序执行。
设计:
利用PM中XPBuffer进行写合并,但写入流太多很难进行写合并。所以需要减小写入流,最好进行顺序写入。由于rdma write会带来大量的写入流,所以采用双边RDMA并且使用SRQ(share receive queue)和多包接收队列(MP RQ)。
主要思路:
(1)所有send到主机的数据均由主机端共享的SRQ进行接受,主机只需要向SRQ中不断压入连续地址,那么接受到的数据将被写入一段连续的PM地址,则可以利用XPBuffer进行写合并。并且由于一个主机只有一个SRQ,说明最终写入PM的写入流只有一个,不会造成XPBuffer难以缓存的问题。
(2)多包接收队列对设计进行进一步优化,使得主机发送到SRQ中的一个recv原语可以接受多个send请求,可以降低CPU在控制路径上的参与率,使CPU不至于成为瓶颈,并且可以解决变长大小的send数据包问题。
SRQ以及多包接受队列知识拓展:
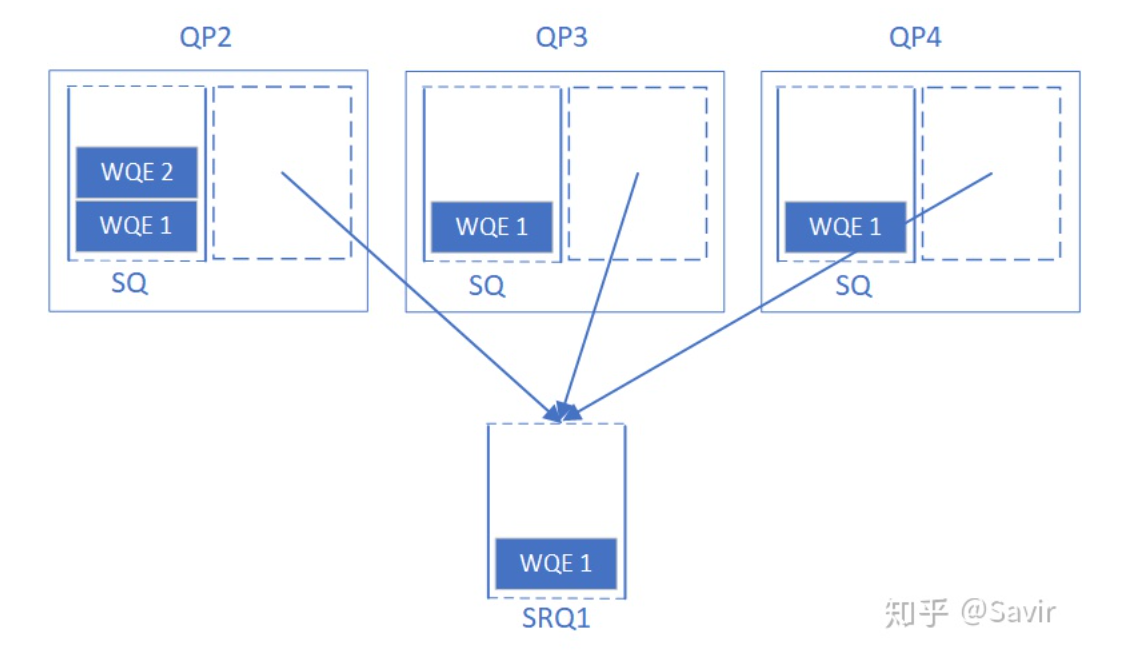
SRQ:
全称为Shared Receive Queue,即共享接收队列。RDMA通信的基本单位是QP,每个QP都由一个发送队列SQ和接收队列RQ组成。SRQ是IB协议为了给接收端节省资源而设计的。我们可以把一个RQ共享给所有关联的QP使用。当与其关联的QP想要下发接收WQE时,都填写到这个SRQ中。然后每当硬件接收到数据后,就根据SRQ中的下一个WQE的内容把数据存放到指定位置。
通过使用SRQ,可以:
1)减轻接收端CPU参与,只有一个SRQ则可以使用一个控制线程,按递增地址顺序将持久内存中的缓冲区推送到接收队列中。发送方只需要对远程持久内存写操作进行RDMA SEND操作,并等待接收方RNIC生成的确认(ACK)。
2)合并来自不同连接的写操作。
MQ RQ:每个recv缓冲区可以接受多个send。send的数据append到buffer之后。这样可以保证连续的写入且支持可变大小的写操作。
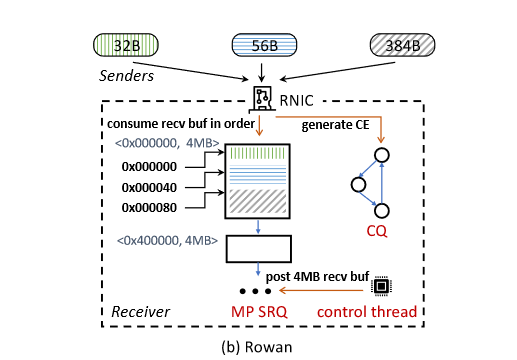
实现:
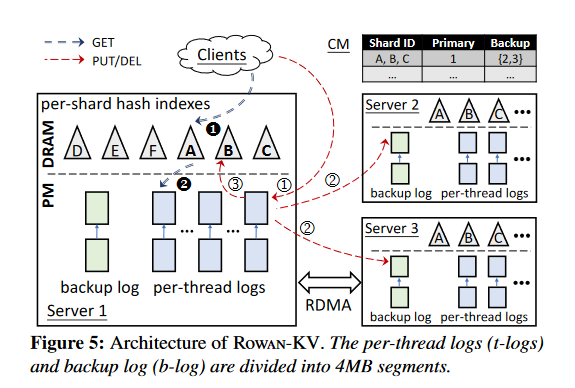
本文进一步实现了ROWAN-KV,一个采用ROWAN进行主从备份的PM KVS。它采用日志结构的方法来管理本地PM写和远程PM写,因为日志结构是append方式修改,所以是顺序写入,可以利用XPBuffer进行写合并。具体而言,每个服务端在PM上维护每个线程私有的主日志和节点唯一的备份日志。对于PUT请求,工作线程生成对应日志项,将日志项持久化到主日志中,并通过Rowan将日志项同步到每个备份节点的备份日志中。对于GET请求,线程通过DRAM中的索引找到对应的日志项。
实验结果:
RoWAN可以将写放大降低到1.056x。如下图所示,在有大量并发远程小型写入的情况下,Rowan 可以在很大程度上消除写放大问题。当不存在本地 PM 写入时,DLWA 小于 1.029 倍。因为 Rowan 可以将远程小写入合并为单个写入流,从而在PM的XPBuffer中实现高效的写入合并操作。最右边的图为RDMA单边原语写操作与RoWAN的对比,RDMA单边写由于网络的异步性会造成大量的并发小写,从而降低了PM的吞吐。

在延迟方面,RoWAN虽然使用了共享接收队列,但并没有使得请求的延迟增加。在只读负载下,RoWAN比RPCKV更慢是因为RoWAN关闭了RNIC的DDIO功能,从而降低了网卡性能。DDIO可让 RNIC 直接将 DMA 数据传输到末级缓存,禁用DDIO的目的是为了让数据能够从网卡持久到PM中而不是cpu cache。在只写和写密集情况下,RoWAN的延迟表现都很低,也符合其设计。

总结:
亮点:
使用RDMA two side的SRQ进行消除合并写,但数据传输仍然享受了rdma one side的效率。
缺点:
本文采用日志结构的KV系统, 且每个线程对应一个t-log。那么在后台线程进行索引更新的时候会随着线程数的增多而耗费更多的时间,造成可扩展性问题。共享的CQ会造成竞争问题。
相关论文:
FaRM:nsdi14-paper-dragojevic.pdf (usenix.org)
该论文是利用RDMA单边原语进行构建分布式KVS,算是分布式KVS的开端。