Efficient Multi-GPU Shared Memory via Automatic Optimization of Fine-Grained Transfers
摘要
尽管对于GPU间的通信机制在不断的研究,但是如何在多GPU系统提高性能仍然是一个非常大的挑战。
GPU 通信在关键的执行路径上仍然存在很大的传输延迟,这些传输时间不能被掩盖,因为这些传输时间在逻辑上是在两个计算之间的。以上是基于DMA的传输框架
但是细粒度的点对点内存访问内核执行导致内存停顿可能超过GPU 通过多线程处理这些操作的能力。更糟糕的是,点对点的传输数据的性能非常差。为了解决这些问题,我们提出 PROACT,一个支持远程内存传输的系统,具有点对点传输的可编程性和管道优势,同时实现可媲美的批量 DMA 传输互连效率。结合编译时检测对每个数据块的准备情况进行细粒度跟踪GPU、PROACT 支持互连友好的数据传输同时在内核期间通过流水线隐藏传输执行时延。
效果是4个GPU可以达到单个GPU性能的三倍 16个GPU的系统可以达到单个GPU性能的11倍
引言
尽管现在的研究都在致力于提高多核GPU的峰值性能,但是当下的多核GPU系统的性能仍然存在一定的挑战,为了充分利用多核GPU的性能,需要将应用的数据结构设计成跨物理内存的,还需要将数据的计算与分发的时间进行一定的切割,这样出现的问题就是多核GPU系统在分发数据的时候不做计算,计算的时候不传输数据。
为了提高多GPU系统的使用率以及整体的性能,现在的开发人员需要
- 性能调优
- 重新架构应用程序保证数据分布
- CPU通信和同步管理
这些都需要对于底层的GPU架构、GPU互联以及内存应用程序有深入的了解,所以非常不方便
问题:很难将GPU的计算和通信时间进行重叠
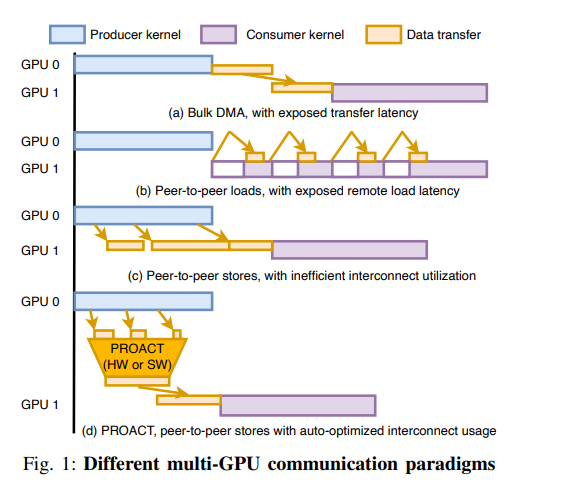
DMA模式
在传输期间,因为是批量进行传输的,存在一个批量同步的问题,所以在传输期间,GPU的计算无法进行
P2P模式
点对点模式可以让GPU直接使用远端的GPU内存,并且可以同时启用计算和传输,但是传输效率非常低下。
- 存在一个stall load
- 大量的小数据访问 store 现在的传输协议PCIE NVLINK小数据的传输效率都很差
PROACT
优化的P2P编程模型
- track data generation 追踪数据生成
- perform transfer coalescing 计算传输合并
- dynamically issue transfers 动态传输
当数据生成后立刻传输
在16个GPU上达到了单个GPU的11倍性能,是次优方案的5.3倍
背景
CUDA 编程模型
定义函数为kernel GPU的编程
https://www.cnblogs.com/skyfsm/p/9673960.html
GPU中存在很多的线程,一个被定义为Kernel的函数只能在一个GPU上运行
kernel启动所需要的所有线程被称为一个网格(grid),每个网格下面还有线程块,共享全局内存
- SP:最基本的处理单元,streaming processor,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
- SM:多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。
GPU间通信机制
基于DMA的大量数据传输
可以满足大规模的数据访问,但是对于小的数据规模,几个缓存行或者是中型的数据规模(KB)并不是非常适合,因为这个初始化以及同步的开销非常大
点对点数据传输
load 存在一个load stall
store 性能比较差,存在大量的小数据写
程序化的连接库 动态的选择两种互联模式进行优化
GPU互联效率
PCIe NVLink AMD’s Infinity Fabric
PCIe和NVlink在小数据量的访问上性能都很差
PROACT 的设计和实现
希望同时获得DMA模式的大规模数据传输以及点对点模式的计算传输同时进行的能力
具体目标
- 平衡传输和计算的重叠
- 最大化合并写入的机会
- 平滑互联的利用率保证没有带宽被浪费
- 通过确保传输的粗粒度来保证传输效率
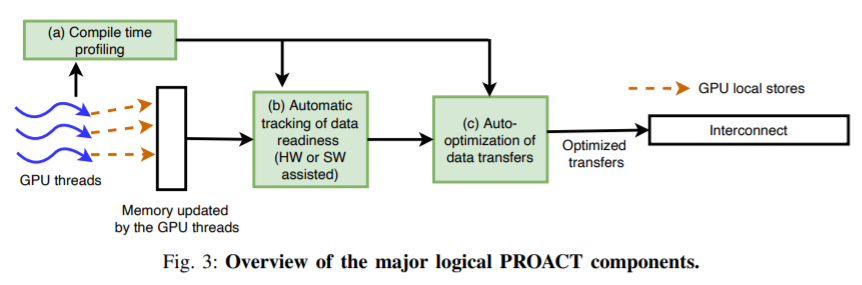
Optimizing Transfer Efficiency via Profiling
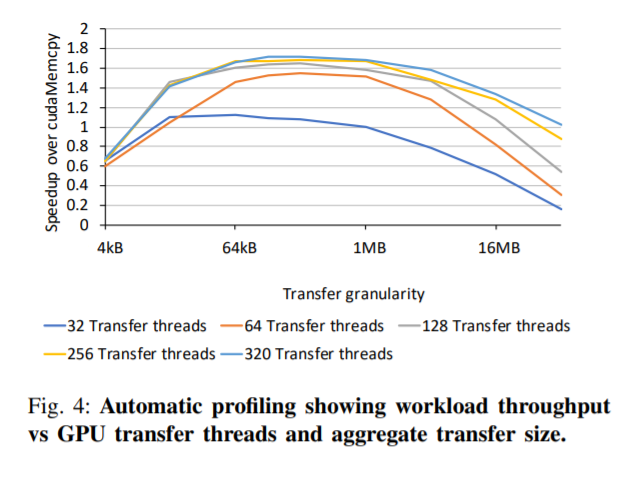
根据每个应用进行分析,需要多少线程进行计算,多少线程进行数据传输,在满足的带宽的情况下,尽量让更多的线程去进行数据传输
compile time profiling,软件配置。做的事情就是选择合适的传输机制(后面再讲),确定传输的粒度和传输的线程,然后确定最适合的相关配置来实现应用可以获得最好的执行时间
Tracking Local Data Transfer Readiness
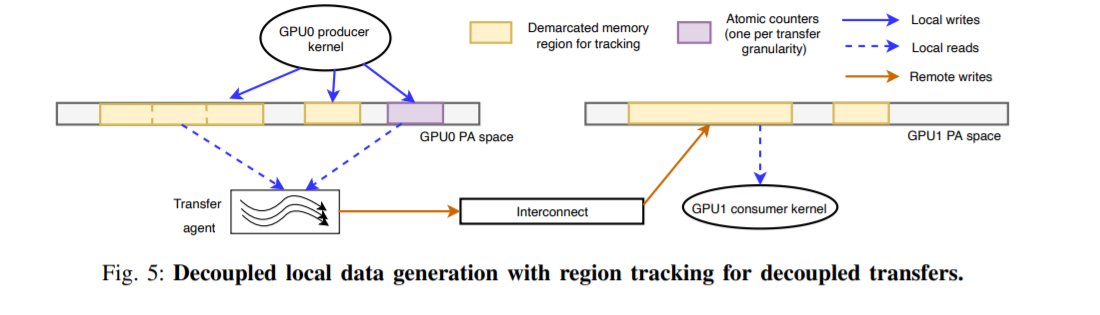
主要的做的就是本地GPU产生数据与传输给远端GPU进行分离,这样可以方便进行下一步的操作
然后引入了一个计数的机制,可以记录已经产生的数据量
Choosing the Decoupled Data Transfer Mechanism
上一步已经将数据传输传输与本地数据生成解耦,这样就可以灵活地选择 GPU 间传输机制 和传输粒度,可以最大限度地提高 GPU 之间的带宽利用率。,因为GPU DMA 的启动开销 引擎不适合频繁的数据移动 然后介绍了三种可以选择的GPU传输机制
Polling
通过设置粒度以及原子化计数本地的数据产生,当达到了设定的阈值,传输模块就会开始工作,然后远程写给远端的GPU,同时分析器会尝试尽可能的降低写的次数
这里还有一些生产者kernel与消费者一致性问题,以及数据产生与传输的解耦问题,在之前讨论过
CUDA Dynamic Parallelism简称CDA
利用的是CUDA模型的父子kernel机制
一致性通过CUDA来保证,仅在传输时消耗计算资源,polling是整个运行期间都要消耗计算资源
缺点是启动开销高,高于于polling但是仍然低于DMA
PROACT将CDA作为一个备选的传输机制,当达到了预定的阈值,然后就会开启传输,把所有的打包好的SM数据给远端GPU
CUDA这里的传输线程数量是也是给定的,只在CDA传输开启时使用,Polling的传输线程是专门用来传输的
Direct Inline Stores
这个就是原来的P2P的传输机制,存在的问题是大量的小数据写,导致性能很差,优点是没有分离数据传输与产生的开销,只要远程写入是均匀的,可以尽量进行合并,这个开销是最小的,但是性能也是最差的,作为最后的选项。
硬件支持
启动PROACT
PROACT的区域
计数器以及通知传输启动的模块
讨论
处理的主要是多核GPU传输问题的开销
- 因为GPU的交流问题导致的低扩展性
- 写访问模式没有特殊的设计
- 程序员进行结构性的编程
但是如果是瓶颈在于GPU计算上的话,带来的PROACT带来的提升并不明显,但也仍然可以带来一定的提升
注意
PROACT与NVLINK NVSWITCH的区别:
PROACT暂时没有产品,但是NVLINK NVSWITCH已经在英伟达的最新产品上使用了,NVLINK NVSWITCH与PCIE一样都是多GPU互联协议,它们都支持DMA以及P2P这两种传输机制,本文的PROACT是对于互联协议中传输机制的优化