PF-DRAM: A Precharge-Free DRAM Structure
1. 背景介绍
DRAM在每次读、写、刷新之前都需要预充电(Precharge),将bitlines的电压稳定在VDD/2。
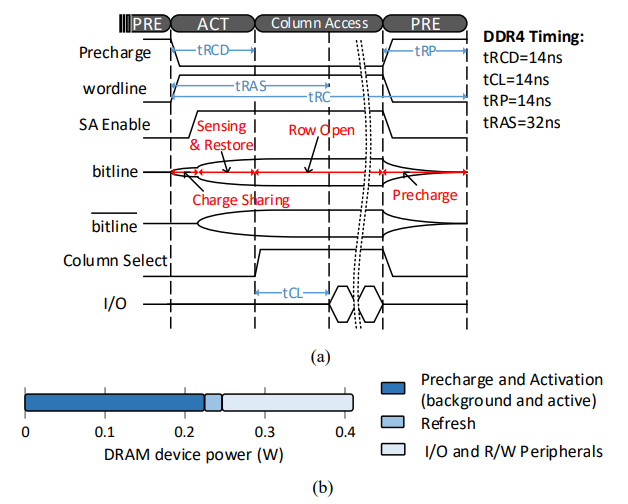
如上图,PRE阶段在整个读、写周期占用的时间较长,Precharge和Activation占用了大部分的DRAM能耗。因此本文设计出不需要Precharge的DRAM电路结构,从而节省DRAM整体能耗的同时提升性能。
2. 传统DRAM工作过程
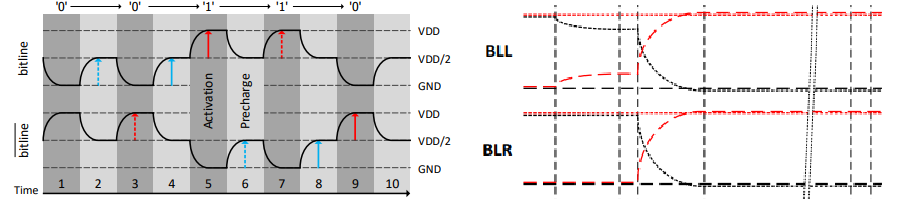
传统DRAM一次操作过程包括precharge,charge sharing,sensing,restoration,column select共5个阶段。
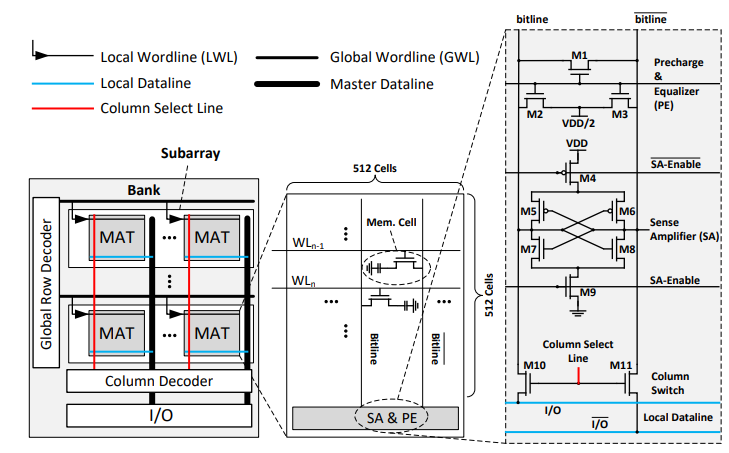
阶段1 Precharge
激发PE信号,M1、M2、M3导通,bitline和bitline非的电压都稳定在VDD/2。
阶段2 Charge Sharing
激发WordLine(WL)信号,Storage Cell中三极管被激发。若存储的数据为逻辑1,则电荷流向bitline,bitline的电压超过VDD/2。若存储的数据为逻辑0,则电荷从bitline流走,bitline的电压低于VDD/2。
阶段3 Sensing
激发SA-Enable和SA-Enable非信号,SA和SA非的电压分别为VDD和0。存放1时,由于bitline的电压比bitline非高,M6、M8的导通性比M5、M7好,bitline的电压逐渐充电到和SA一致(VDD),bitline非的电压逐渐和SA非一致(0)。
阶段4 Restoration
bitline 线处于稳定的逻辑 1 电压 VDD,此时 Bitline 会对 Storage Capacitor 进行充电。经过特定的时间后,Storage Capacitor 的电荷就可以恢复到读取操作前的状态。(每次操作后都会有电荷损失,因此隔一段时间需要刷新以维持存储数据的稳定)
阶段5 Column Select
CSL信号激活,M10和M11导通。读操作则将bitline上的电位传输到I/O线上,写操作将I/O线的电位传输到bitline并执行write Recovery。
3. PF-DRAM工作过程
PF-DRAM的BLL和BLR不需要预充电,而是一直保持相同的电压。当本次访问的数据(Storage Cell电压)和上次访问的数据(BLL/BLR电压)相同时,不需要任何充放电操作。当两者不同时执行翻转操作,将BLL和BLR的电压翻转。
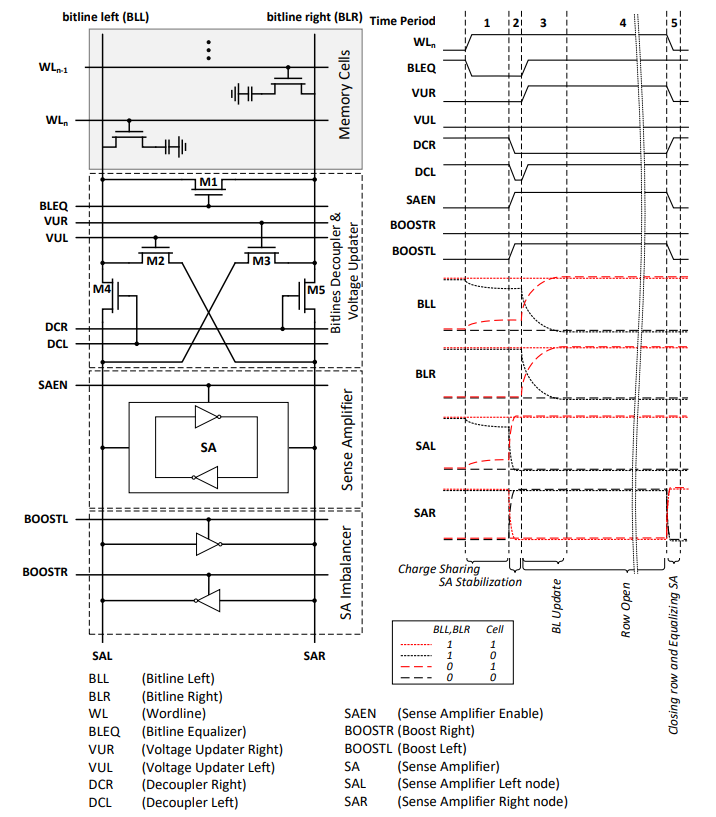
阶段1 Charge Sharing
WL和BLEQ信号打开,M1和Storage Cell导通,BLL、BLR、SAL、SAR维持相同的电压。若Storage Cell的电压和BLL不一致,会发生电荷流动,对BLL造成大小为Vspf的电压变化,Vspf = VDD * Ccell / (CBL + Ccell)。
阶段2 SA Stabilization
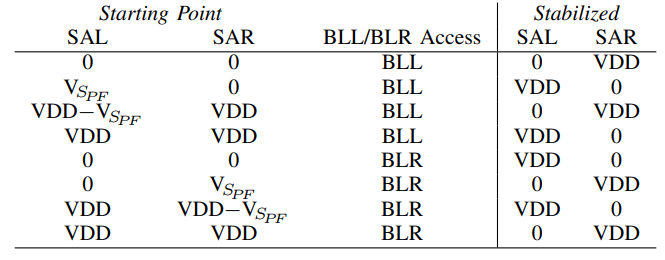
关闭DCL和DCR,打开SAEN,SA电路和Bitline隔离。打开BOOSTL。通过感知放大电路和SA Imbalance电路可以将下表中SA的起始态转化为相应目标稳定态。
阶段3 BL Updater(Restoration)
在阶段3开始时并行激活CSL信号进行数据的I/O。 打开DCL和BLEQ,M1和M4导通。给BLL和BLR充/放电到与SAL电压维持一致(VDD/0)。若数据没有发生翻转,此时SAL和Bitline电压其实是一致的,仅当从0->1时需要充电。
阶段4 Row Open
PF-DRAM按照open-row方式进行激活,即一次激活整个8KB页对应的bitline,进行完一次64B大小的I/O后保持SA激活,若数据的空间局部性较好,下一次I/O继续命中该row,则可以直接进行数据的I/O。
阶段5 Close Row and Equalizing SA
关闭WordLine从而截断对存储单元的访问。关闭SAEN,BOOST等,激活DCL、DCR,保持BLEQ激活,Bitline的电容远大于SA,SAL和SAR的电压与Bitline保持相同。
4. 对比
4.1 设计区别
- 在PF-DRAM中,Bitline只在它关联的存储单元的当前值和前一次访问的值不同时会发生电压翻转。而不像传统DRAM中无论任何情况下Bitline都需要进行相同的充放电过程。
- PF-DRAM访问延迟中的tRP(Row Precharge latency)不再存在。
- PF-DRAM访问延迟中的tRCD(Row to Column latency)缩短。因为从SA中移除了部分对Bitline的充放电过程。
- PF-DRAM不再需要VDD/2的电压源。
- PF-DRAM相对主流DRAM电路的结构改动最小化了, cell arrays没有修改。
- PF-DRAM可以应用在所有的JEDEC DRAMs上,并且可以和之前提出的节省能耗的DRAM技术并行工作。
4.2 充放电过程对比
4.3 能耗对比
传统DRAM单次操作的能耗如公式(4)所示,其中β取0.54。
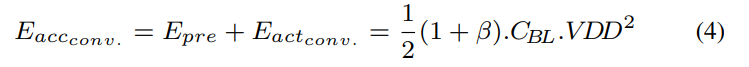
PF-DRAM单次操作的能耗如公式(6)所示,其中P(0->1)是存储单元的数据从0修改为1的概率。
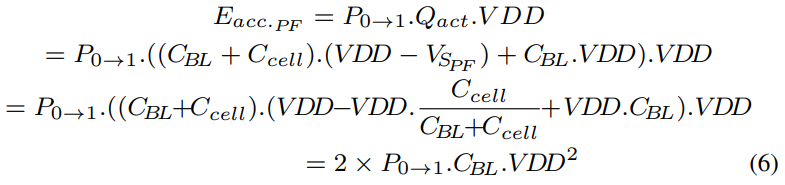
使用SPEC CPU2017和PARSEC 2.1在1-core, 2-core, 4-core, and 8-core仿真系统测试显示在连续激发的过程中数据翻转的平均概率依次为9.1%, 11.0%, 11.9%, and 13.6%。 可见P(0->1)不是很大,正常情况下PF-DRAM的单次操作过程能耗远小于传统DRAM。即使是在完全随机的读写情况下,0->1的概率为25%,PF-DRAM的单次操作能耗也只有传统DRAM的64%。在连续I/O请求都是0->1翻转,且行命中率为0的最坏情况下PF-DRAM的能耗比传统DRAM高29%。
5. 实验
A.功能性
B. 稳定性
-
过程突变:
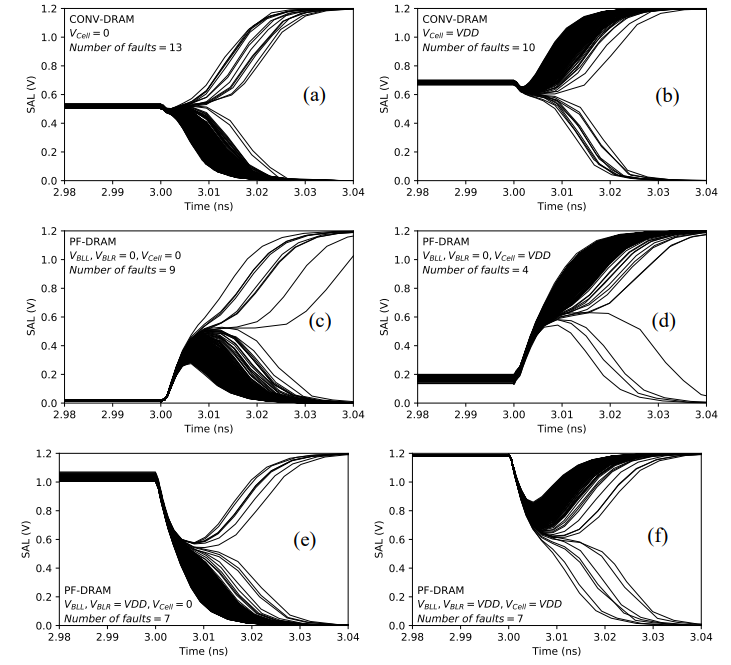
图像显示,传统DRAM的错误率为0.58%,PF-DRAM的错误率为0.34%。
-
噪音干扰:传统DRAM读’0‘和’1‘时可容忍的干扰电压阈值为80mV,而PF-DRAM在读取数据时cell与bitline一致和不一致时的阈值分别为85mV和90mV。并且,在SA放大时,PF-DRAM中Bitline和SA断开了连接,避免了干扰。
C. BitFlip Probability
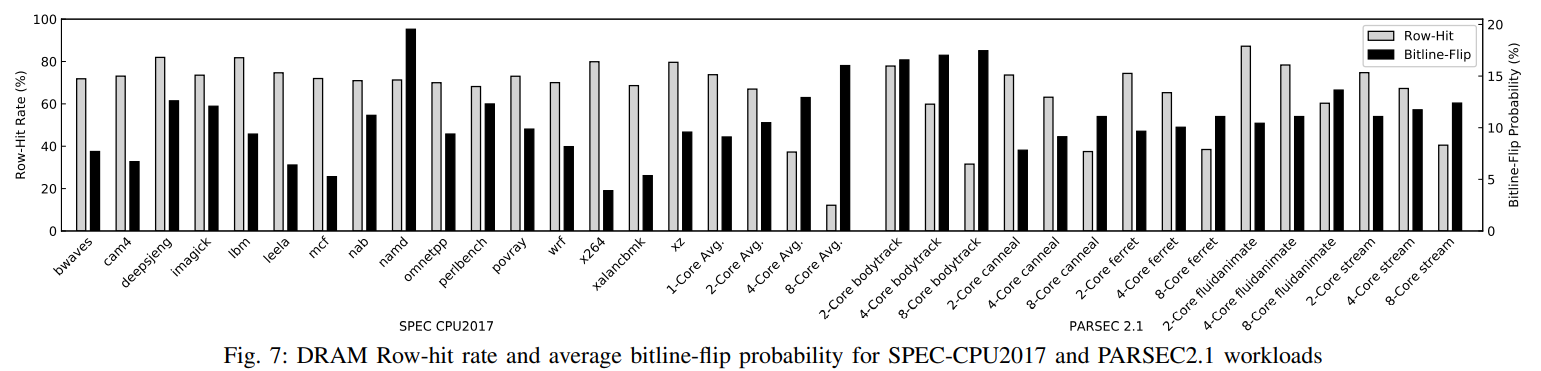
- 行命中率:从1核到8核处理器,负载的平均行命中率由73.8%下降到12.4。这是由于多线程减低了数据的空间局部性。
- 位翻转率:SPEC CPU2017上不同负载测试平均位翻转率为9.1%(单核)、10.5%(2核)、12.9%(4核)、16.0%(8核)。
D. 性能提升
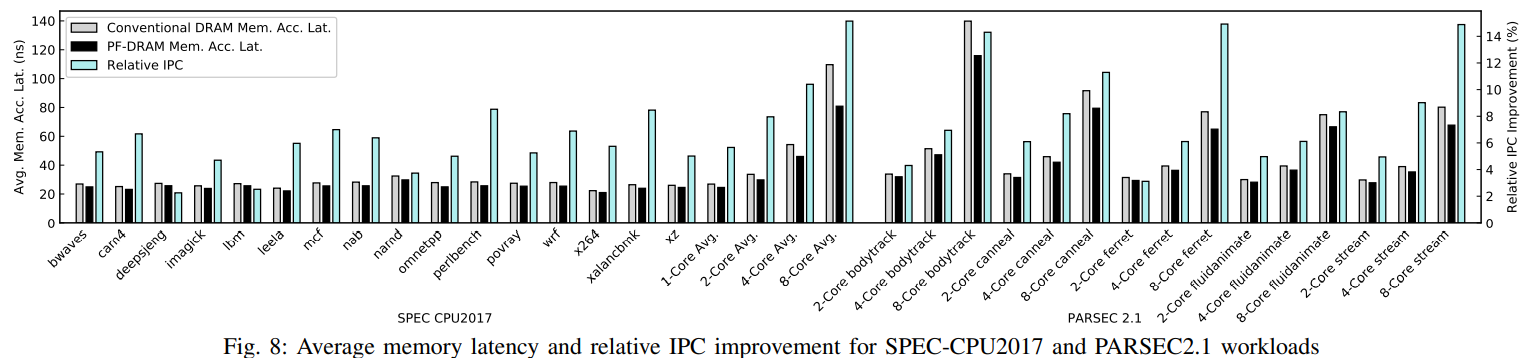
SPEC CPU2017 benchmark suite:单核平均时延提升2.1 ns (7.8%)。2, 4, 8核分别提升3.9 ns, 8.3 ns, and 28.8 ns (11.5%, 15.2%, 26.3%).
E. 能耗
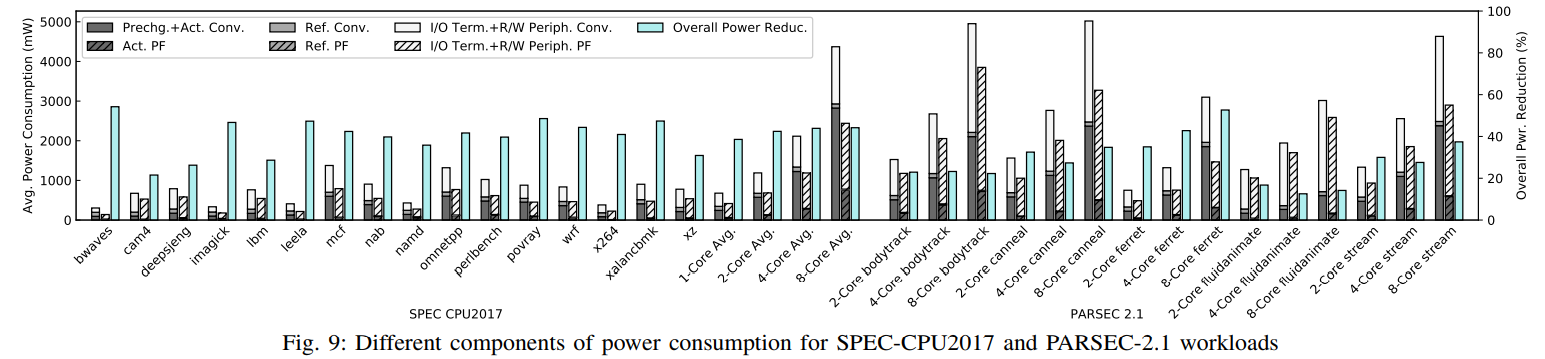
SPEC CPU 2017:单核, 2-core, 4-core, and 8-core的平均能耗减少38.5%, 42.4%, 43.8%和44.1%。cam4负载提升最少,为21.5%;bwaves负载提升最多,为54.2%。
F. 空间开销
M4和M5大概占用0.8%的空间,SA Imbalancer电路大概8%的空间。
G. 架构优化
- 对数据的调度策略进行优化,充分利用bank并行结构,降低位翻转率。
- 对操作系统的内存页管理进行优化,来降低位翻转率。
- 不需要Precharge后,可以简化内存访问调度。(less states and shorter reordering queue)
- DRAM Page大小减小:目前多线程负载的行命中率低,没有必要使用open-row,而PF-DRAM让row打开的能耗降低。
6. 总结
PF-DRAM只在存储单元数据与bitline数据不一致时执行flip操作。实验显示,相对传统DRAM,PF-DRAM平均能耗降低约35.3%,总体性能最高提升约24.3%,而只多付出了8.8%的空间开销。