ROART: Range-query Optimized Persistent ART
摘要
在傲腾DCPMM出现后,考虑在实践中应用持久数据结构。
提出三个对持久索引设计有重要影响的方面:功能、性能、正确性。
基于ART提出ROART,三个优化点:1.压缩叶子节点以减少范围查询的指针追踪开销;2.entry压缩、元数据选择性持久化、最小有序分割来减少持久化开销;3.设计内存管理避免内存泄漏,即时重启消除恢复时间。
性能提升:对于基数树1.65×,对于B+树1.17-8.27×。
1. 引言
指出影响持久索引设计的三个重要方面。
1.1 功能:变长Key和范围查询
变长key对于真实系统很重要:RDBMS(MySQL)、KV Stores(RocksDB)等;范围查询用于支持现实世界的应用程序中的不等号比较。
1.2 性能:持久化开销
为保证崩溃一致性,操作完成时必须通过cacheline flush和memory fence持久化到NVM。NVM的写吞吐量比读要低,且持久化操作比普通的写操作开销更大(2.4×以上)。
1.3 正确性:异常解决和内存安全
异常:lost update、dirty read,会导致系统崩溃重启时已成功操作的影响消失。
内存泄漏:不一致的内存分配元数据、非阻塞数据结构设计中使用的惰性GC。
1.4 树和哈希的选择
为支持范围查询,选择修改基于树的索引而非哈希。
B+树支持变长key开销很大,因此选择优化基数树范围查询功能。
其他基数树:(1)WORT:写优化,不支持多线程;(2)P-ART:由易失性ART根据RECIPE原则(SOSP’19)转换为并发持久性基数树,对变长key和范围查询无优化。
以上两个都没有考虑内存安全。
在此基础上提出ROART。
范围查询改进:叶子压缩,延迟了叶子分裂,并将多个叶子节点压缩成一个叶子数组。这种技术的好处有三个方面。首先,它减少了范围查询期间的指针跟踪。其次,它可以减少复杂的分割操作的数量。最后,它倾向于降低树的高度,这对所有的索引操作都是有利的。
减少持久性开销:(i)在8字节条目中结合键和子指针的条目压缩(EC);(ii)选择性元数据持久化(SMP),减少需要持久化的元数据量;(iii)最小有序拆分(MO),它放松拆分操作中步骤的顺序,以减少sence指令的数量。前面提到的LC在这里也有帮助,因为它延迟了叶节点分割并减少了持久化开销。
正确性:instant restart。
2. 背景
2.1 索引功能
2.1.1 变长key
变长key应用更加广泛,但是有代价。
很多B+树变体及FAST&FAIR只支持8B定长key。定长的优势在于减少clwb数,具有出色缓存局部性,高遍历性能。
一种简单的支持变长方法:定长区域用作指针,指向真实数据。问题:导致pointer chasing开销,如下图,变长的吞吐量大幅降低。

2.1.2 范围查询
范围查询是RDBMS和KVS的重要特性。本文重点是基于树的索引,天然支持范围查询。
B+树有效支持范围查询,因为多个key存储在用一个叶节点,但是很难支持变长key。
基数树、二叉搜索树的key可以存储在叶节点和内部节点,因此范围查询必须遍历树的不同层,解引用更多指针,随机访问次数多。
NVM顺序读和随机读性能差距比DRAM中大。
最终选择优化ART。
2.2 性能
NVM支持崩溃一致性需要显式持久化。然而持久化指令如flush、fence开销昂贵。
只有一些通用的优化用于支持持久性操作,但是没有优化来减少持久性操作数量。
一些工作提出了专有的优化来减少持久化开销。wB+Tree、NVTree、FPTree、LB+Tree放弃叶节点中key顺序,减少了插入和删除的写操作;FAST&FAIR、LB+Tree尽可能使数据共享cacheline,减少持久性操作;RNTree使用HTM来增加原子写粒度,减少持久性操作数量。
上述工作均利用了各自数据结构的属性,本文利用ART的固有特性来优化持久性。
2.3 正确性
2.3.1 异常解决
设计无锁的非易失性数据结构时容易发生两种异常:丢失更新(lost update)和脏读(dirty read)。
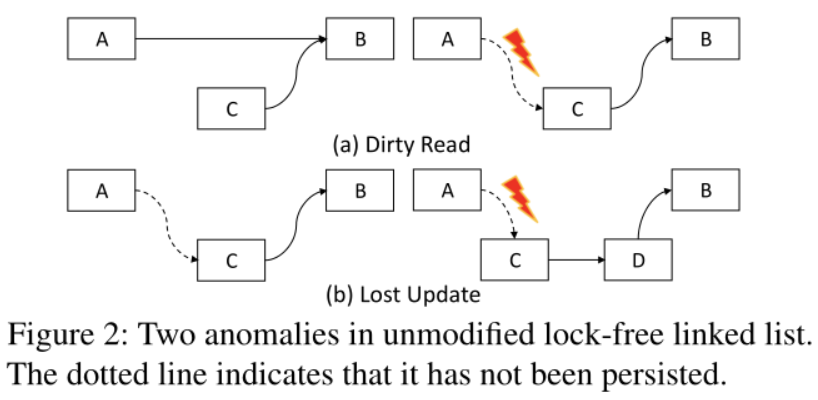
对于无锁设计:可以使用link-and-persist、PMwCAS(如SkipList和BzTree)。
对于有锁设计:可以使用non-temporal store代替temporal store(如P-ART)。
2.3.2 内存安全
内存泄漏:
-
原因:分配/回收操作、惰性GC的元数据不一致。
-
正确的NVM分配器分为两类:基于日志的分配器(日志记录确保操作原子性)、崩溃后GC(恢复期间扫描内存空间回收垃圾数据)。
-
评估5个常用的NVM分配器:malloc、libvmmalloc、PMDK、nvm_malloc、Makalu。
垃圾回收:
-
惰性GC用于支持非阻塞查找,提高读性能,会导致内存泄漏,因为标记垃圾数据的元数据不会被持久化。
-
简单地对元数据修改添加持久化操作,会降低25.7%的性能。
-
崩溃后GC减少正常操作中的持久化开销,但会增加恢复时间。
-
改进机会:既不引起正常操作中的持久化开销,也不遭受长恢复时间。
3. ROART设计
3.1 现有基数树
ART:节省空间的基数树
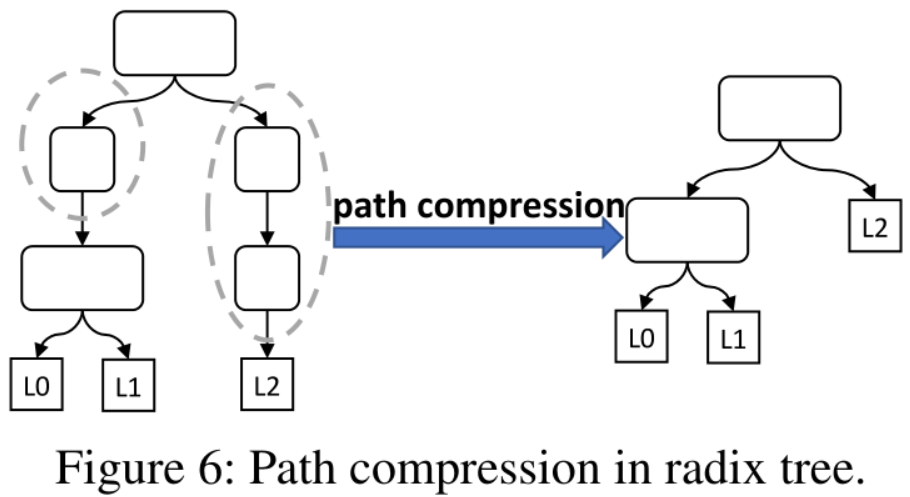
路径压缩:将只有一个子节点的节点合并到其子节点,降低基数树高度
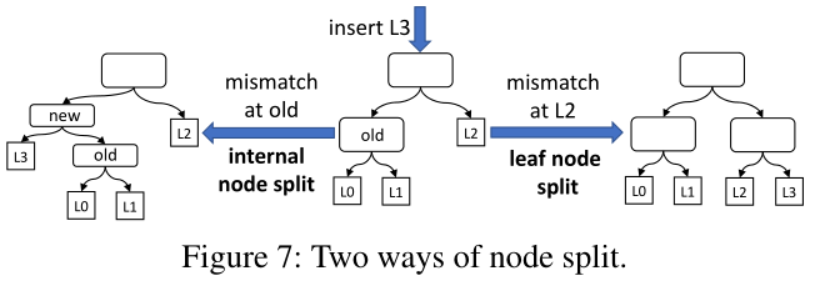
节点分裂:分为内部节点拆分和叶节点拆分
持久性变量:现有方法RECIPE通用但低效
3.2 ROART结构
基数树范围查询表现较差,做如下修改,内部节点按顺序包含更多叶子。
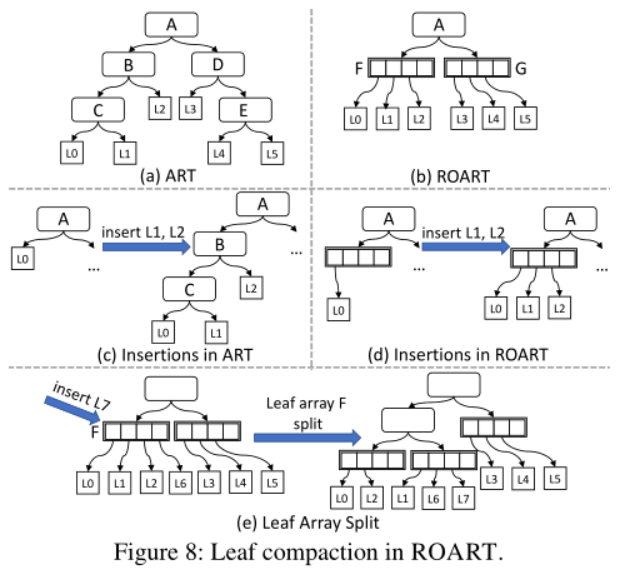
叶子压缩有几个好处:
- 减少范围查询的指针数量
- 减少根到叶子路径的长度和遍历开销
- 减少插入的持久化开销。
3.3 减少持久化开销
ROART提出条目压缩(Entry Compression)将key的关键字节打包到N4、N16和N48中的指针(使用48位)中。由此产生的条目(empty: 8位;键:8位;指针:48位)称为Zentry。
由于Zentry是8字节的,可以原子地更新,因此与ART相比,EC减少了用于持久化ROART中的每个条目的一条持久指令。
3.3.1 选择性元数据持久化
并非所有元数据都需要持久化。
ROART在NVM中维护一个global generation number (GGN)。每次重启时,GGN都会增加。ROART中的每个节点都有自己的持久节点生成号(NGN)。当NGN = GGN时,表示该节点的元数据是最新的。否则,恢复该节点的元数据,然后将GGN分配给NGN。
3.3.2 最低限度要求分割
内部节点拆分有四个步骤:
- 分配一个新的叶子L3
- 分配一个内部节点,标记为new,有两个子节点(L3和node old)
- 改变父节点的指针
- 更新old的前缀(图中没有显示)
步骤1、2对其他线程不可见,3、4顺序不重要。因此先执行1、2、4,使用一个sfence,再执行3,并调用第二个sfence。将sfence指令数量从4个减少到2个。
3.4 正确性
3.4.1 ROART中的异常处理
ROART类似ART-ROWEX的并发控制策略,无锁读和有锁写。
使用non-temporal store来修复异常。
3.4.2 延迟检查内存管理(DCMM)
DCMM使用两层体系结构。
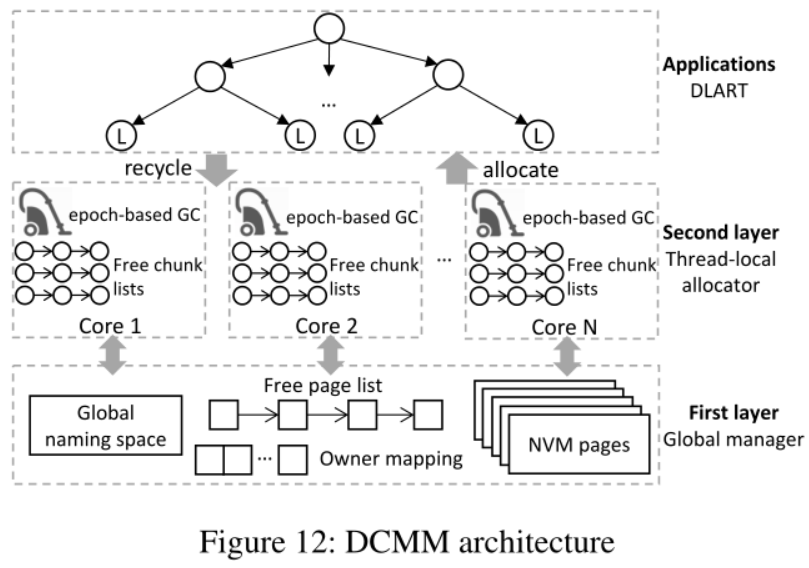
第一层:全局内存管理器,以页面粒度管理整个NVM区域(页池)。
第二层:每线程的分配器,类似buddy系统,空间不够时向第一层申请页。
5. 相关工作
基于树的持久化索引
CDDS Tree首先提出了一个多版本的持久性B+树设计,它使用copy-on-write技术,而不覆盖原始条目,但是持久化开销很大。DPTree提出了一种批量修改DRAM缓冲区的方法,以减少持久化开销,但它需要一个后台合并进程,这可能会导致前台请求暂停,并消耗额外的NVM带宽。
µtree关注持久索引中的尾部延迟,这是一项正交工作。
持久化哈希索引
持久哈希索引可以支持快速点访问,但对范围查询有困难。Level hashing提出了一种新的两级哈希表结构,减少了调整大小的开销。Clevel hashing是level hashing的多线程版本,基于无锁方式和并发的后台调整操作。CCEH提出了一种基于可扩展哈希的三层结构来减少NVM的写操作。Dash采用乐观并发控制来提高CCEH的并行性,并提出了桶负载均衡策略来提高哈希表的负载系数。
通用转换方法
通用方法通常提供更简单的解决方案来实现持久索引,但对性能的优化较少。Izraelevitz等人设计了一种将任何非阻塞的瞬态数据结构转换为非阻塞的持久数据结构的方法,方法是在读取或存储指令之后添加flush和fence指令,但会造成严重的持久化开销。David等人提出了一种link-and-persist方法来实现无日志并发数据结构,并保证持久的线性化。但它只能应用于8字节存储/CAS指令。