HTMFS: Strong Consistency Comes for Free with Hardware Transactional Memory in PersistentMemory File Systems
Brief
问题
相比与普通SSD,ZNS节省了主控和DRAM的开销,如果可以用到RAID上会有明显的价格优势。但是将ZNS组成RAIZN(对上暴露的是一个逻辑ZNS盘),需要面临以下挑战
- 元数据管理 ZNS无法原地更新数据,这就意味着新的元数据设计
- Parity更新 对于stripe未对齐的写,Parity需要多次更新,但是ZNS不支持原地更新数据
- Stripe单元写的原子性保证
对于Stripe写涉及到多个设备,可能会出现断电后数据没有完全写入的问题(torn write),在普通RAID中,SSD可以覆盖写,因此这个问题可以简单地认为这个Stripe未成功写入,下次再被新的stripe覆盖写入即可。但是在ZNS中,无法覆盖写,那么这个失败写入的stripe无法被新的stripe覆盖。
解决方案
- 元数据: 对于不同类型的元数据进行分类,使用log-structured方式储存,并且在内存中缓存一份用于读取。(其他还有一些细节的,比如元数据的垃圾回收,选择放置元数据Zone之类的问题)
- Parity更新 元数据采用log形式,因此可以append一条新的元数据record(占用64KB),当stripe满了再写入。其一致性保证和垃圾回收这些都由元数据管理模块来管理
- torn write解决
append一条新元数据record,将失败写入的stripe remap到元数据中(64 kb)。其中也有可能出现多次失败写入,创建了大量stripe remapping record,从而导致元数据zone空间不足。对于这个问题,文中的解决方案是,在每次重启RAIZN后,检查是否remap record超过了用户设置的阈值,如果超过那么重建remap record所在的zone,既把有效数据拷贝出来,然后reset zone,再写入。由于只在开机的时候操作,因此认为对性能无额外影响。
结论
这篇论文证明了RAIZN能够达到与modaid level 5相当的性能,并且RAID可能会因设备垃圾收集而导致无法预测的严重性能下降,而RAIZN不受影响,因为ZNS SSD不执行设备垃圾收集。
基础知识
①什么是RAID以及各个版本详细对比? https://zhuanlan.zhihu.com/p/567159708 ②RAID中条带的概念?https://www.cnblogs.com/jiweilearn/p/9501285.html#:~:text=%E5%86%8D%E5%9B%9E%E6%9D%A5%E8%AF%B4%E4%BD%A0%E7%9A%84ra,pedepth%E3%80%82 ③RAID5的奇偶校验怎么进行? https://zhuanlan.zhihu.com/p/80361528 在RAID组中,数据通常是按照固定大小的条带进行组织的,而当进行非条带对齐写入时,即写入的数据大小不是条带大小的整数倍时,RAID需要重新计算奇偶校验,以确保数据的完整性和一致性。为了记录这些奇偶校验计算结果,RAID会生成一个奇偶校验日志,以便在需要时能够进行恢复和修复
介绍
相比与普通SSD,ZNS节省了主控和DRAM的开销,如果可以用到RAID上会有明显的价格优势。 背景 简单介绍ZNS及特性,RAID,mdraid RAID将数据组织成条带,由分布在所有设备上的条带单元和奇偶校验组成,条带单元根据阵列初始化参数以算术方式映射到特定设备上的特定地址。 现代RAID通常被实现为一个逻辑卷,它可以被视为一个普通的块设备,比如mdraid(mdraid支持写日志,为写操作提供原子性和持久性——与RAIZN完全兼容)
面对挑战
其实所有的问题都是因为ZNS盘没法覆盖写而导致的 ①元数据管理 ZNS无覆盖写来原地更新数据,所以元数据需要重新设计。 传统RAID的基本元数据由只写入一次的超级块组成,而RAIZN需要额外的元数据来处理不能覆盖这一特点,需要间接或记录的情况,例如部分条带写入或部分区域重置。因为元数据不能被覆盖,所以必须进行日志结构化,这进一步增加了复杂性并需要进行垃圾收集。 ②奇偶校验更新 ZNS无覆盖写来原地更新数据,而当Stripe未对齐的写入时,Parity无法多次更新。 非条带边界对齐的写入操作,由于奇偶更新而降低RAID性能,但对于ZNS设备是一个正确性问题。在ZNS设备中,写入的LBAs在整个区域重置之前不能更改,即在未对齐的写入之后不可能更新奇偶校验。但必须在通知主机IO完成之前写入部分计算的奇偶校验,否则可能会发生数据丢失。 ③Stripe写原子性 在ZNS中无法覆盖写,那么因为断电写入失败的stripe无法被新的stripe覆盖。 对于Stripe写涉及到多个设备,可能会出现断电后数据没有完全写入的问题(即torn write),在RAID中SSD可以覆盖写,因此这个问题可以简单地认为这个Stripe未成功写入,下次再被新的stripe覆盖写入即可。 ④区域重置原子性 RAIZN的reset涉及多个物理区域,断电会导致部分区域reset而另一些未reset 重置RAIZN区域时必须小心,因为它跨越多个物理区域。这样的请求将被转换为涉及的所有物理区域的重置,但这些操作不是原子性的,这意味着系统可能在重置区域的一个子集后失去电源。在大多数情况下,可以通过检查每个物理区域的写指针来检测这种情况的发生。 ⑤写持久性 给定LBA上的FUA写入被持久化,但同一区域中的前一LBA未持久化,则区域的逻辑地址空间部分将变为不可读 Forced unit access:在FUA命令中,存储设备必须立即将数据写入到永久存储介质中,而不是将数据缓存到设备的缓存区中等待进一步操作。这样可以确保即使发生系统崩溃或掉电等异常情况,数据也能够得到保护并保持持久性 FUA绕过写缓存,在写入被应用程序确认之前,指示设备立即写入数据。如果在给定LBA上的一个FUA写入被持久化了,但是在同一(逻辑)区域中的先前LBA上的数据没有被持久化,那么区域的逻辑地址空间部分将呈现为不可读。所以必须格外小心地处理FUA写操作,以确保在电源或设备故障后可以读取数据。
RAIZN的结构
RAIZN暴露为一个逻辑ZNS盘,核心设计问题是地址空间管理:如何将物理设备上的物理地址PBAs组织成向主机公开的逻辑块地址LBAs。主机应用程序将IO提交给RAIZN,在提交给物理设备之前将请求LBA转换为一组PBA。 ①数据存放和处理 RAIZN类似RAID-5的数据放置方案。每个LBA静态映射到特定的设备和PBA,用户数据被组织成条带,这些条带被划分为条带单元,奇偶校验编码,然后分布在阵列中的各个设备上。 RAIZN接收到的每个IO请求,都会进行奇偶校验计算,缓存部分条带数据,并将数据分成更小的IO提交给物理设备。这些额外生成的物理IOs称为子IOs,包括数据、奇偶校验和元数据。
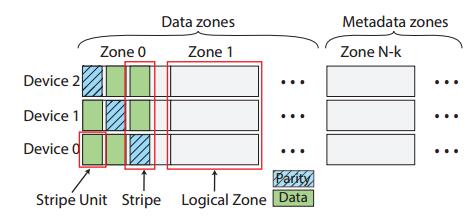 RAIZN中组织物理设备的地址空间如图,物理区域分为数据区和元数据区,元数据区域的数量是可配置的,每个设备至少有3个。数据分区被组织成逻辑分区,每个逻辑分区对应于每个设备的一个物理分区。RAIZN将每个逻辑区域作为仅顺序写入区域呈现给主机应用程序。
②容错性
Degraded 降级读写:指在RAID系统中的一种读取数据的方式,当RAID中的一块磁盘出现故障时,RAID系统仍然可以正常工作,但是会以“降级模式”运行。在降级模式下,RAID系统无法执行完整的数据保护功能,而是从剩余的磁盘中读取数据并组合成完整的数据块,以满足读取请求。由于缺少一块磁盘,降级读取的速度通常比正常读取要慢,并且可能会导致数据的丢失或损坏。
RAIZN的降级读写处理方式与传统RAID相同,缺少条带单元在读时由奇偶校验重构,在写时省略。
但RAIZN重建设备的方式与传统RAID不同,更换故障设备时RAIZN会逐个区域重建新设备。RAIZN优先重建活动区域,已完成的区域。在重建中以降级模式向未重建的开放区域提供写操作。对活动区域进行优先级排序可以最大限度地减少重建的读取开销,最大限度地减少所有进一步写入可以以不降级的方式提供服务之前的延迟。
ZNS设备将磁盘的存储空间划分为多个物理区域,每个物理区域中的逻辑块地址范围是固定的,不允许跨越物理区域。这些逻辑块的地址范围是预定义的,因此ZNS设备可以轻松确定哪些块地址包含有效数据。在进行写操作时,ZNS设备会将数据写入一个逻辑块中,然后将整个逻辑块作为一个单位进行擦除。在进行读操作时,ZNS设备可以快速定位所需的逻辑块,从而实现更快的读取速度
ZNS接口赋予RAIZN的一个优点是能够轻松地确定哪些块地址包含有效数据。RAIZN只重建包含用户写入数据的LBA范围的子集。
③元数据管理
RAIZN有几种类型的元数据,用作被持久化为日志结构更新,以日志格式持久化元数据更新允许RAIZN符合顺序写入约束,并且通过在单个元数据区域中存储多种类型的元数据更新,RAIZN最大限度地减少了保留的元数据区域的数量。RAIZN为部分奇偶校验保留一个区域,为所有其他元数据保留一个区域,以及至少一个区域(称为交换区域)来促进元数据区域的垃圾收集。
RAIZN中元数据的总大小相对较小(<100 MiB),且写入内存中,在重新挂载卷时读取持久副本,并且元数据写入使用append,即使多并发元数据日志写入也确保高吞吐量。元数据子集必须持久化到阵列中的所有设备上(包括RAID参数、设备ID分配、生成散列和zone reset预写日志)。其余的元数据只写入其对应的设备。
单个元数据区域可以为每种类型的元数据保存日志结构的更新,但是RAIZN中的大多数元数据很少更新,但奇偶校验日志在每次非条带对齐写入时生成,并在写入完整条带时失效。对于许多工作负载来说,这可能是非常常见的,因此RAIZN将奇偶校验日志写入单独的元数据区域,从而将系统的其余部分与奇偶校验日志的影响隔离开来。
RAIZN中组织物理设备的地址空间如图,物理区域分为数据区和元数据区,元数据区域的数量是可配置的,每个设备至少有3个。数据分区被组织成逻辑分区,每个逻辑分区对应于每个设备的一个物理分区。RAIZN将每个逻辑区域作为仅顺序写入区域呈现给主机应用程序。
②容错性
Degraded 降级读写:指在RAID系统中的一种读取数据的方式,当RAID中的一块磁盘出现故障时,RAID系统仍然可以正常工作,但是会以“降级模式”运行。在降级模式下,RAID系统无法执行完整的数据保护功能,而是从剩余的磁盘中读取数据并组合成完整的数据块,以满足读取请求。由于缺少一块磁盘,降级读取的速度通常比正常读取要慢,并且可能会导致数据的丢失或损坏。
RAIZN的降级读写处理方式与传统RAID相同,缺少条带单元在读时由奇偶校验重构,在写时省略。
但RAIZN重建设备的方式与传统RAID不同,更换故障设备时RAIZN会逐个区域重建新设备。RAIZN优先重建活动区域,已完成的区域。在重建中以降级模式向未重建的开放区域提供写操作。对活动区域进行优先级排序可以最大限度地减少重建的读取开销,最大限度地减少所有进一步写入可以以不降级的方式提供服务之前的延迟。
ZNS设备将磁盘的存储空间划分为多个物理区域,每个物理区域中的逻辑块地址范围是固定的,不允许跨越物理区域。这些逻辑块的地址范围是预定义的,因此ZNS设备可以轻松确定哪些块地址包含有效数据。在进行写操作时,ZNS设备会将数据写入一个逻辑块中,然后将整个逻辑块作为一个单位进行擦除。在进行读操作时,ZNS设备可以快速定位所需的逻辑块,从而实现更快的读取速度
ZNS接口赋予RAIZN的一个优点是能够轻松地确定哪些块地址包含有效数据。RAIZN只重建包含用户写入数据的LBA范围的子集。
③元数据管理
RAIZN有几种类型的元数据,用作被持久化为日志结构更新,以日志格式持久化元数据更新允许RAIZN符合顺序写入约束,并且通过在单个元数据区域中存储多种类型的元数据更新,RAIZN最大限度地减少了保留的元数据区域的数量。RAIZN为部分奇偶校验保留一个区域,为所有其他元数据保留一个区域,以及至少一个区域(称为交换区域)来促进元数据区域的垃圾收集。
RAIZN中元数据的总大小相对较小(<100 MiB),且写入内存中,在重新挂载卷时读取持久副本,并且元数据写入使用append,即使多并发元数据日志写入也确保高吞吐量。元数据子集必须持久化到阵列中的所有设备上(包括RAID参数、设备ID分配、生成散列和zone reset预写日志)。其余的元数据只写入其对应的设备。
单个元数据区域可以为每种类型的元数据保存日志结构的更新,但是RAIZN中的大多数元数据很少更新,但奇偶校验日志在每次非条带对齐写入时生成,并在写入完整条带时失效。对于许多工作负载来说,这可能是非常常见的,因此RAIZN将奇偶校验日志写入单独的元数据区域,从而将系统的其余部分与奇偶校验日志的影响隔离开来。
 元数据标头:RAIZN中的每个持久化元数据日志都包含一个元数据头,其中包括元数据类型,元数据描述的LBA范围,包含上述LBA的逻辑区域的生成计数器。
生成计数器:它是RAIZN在卷生命周期内唯一标识给定LBA内容的方法,每次重置(逻辑)区域时,其生成计数器增加1。当与LBA配对时,这个单调递增的计数器用于跟踪元数据日志的有效性。此属性是RAIZN元数据管理的关键:如果元数据头包含过时的生成计数器,则由于逻辑区域被重置,与该头关联的元数据将无效。
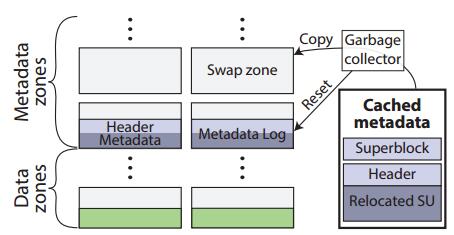
元数据垃圾收集:RAIZN定期对元数据进行GC。RAIZN垃圾收集器使用交换区在不中断操作的情况下促进垃圾收集。RAIZN首先指定一个交换区来替换完整的元数据区,并立即在其中写入任何新的日志条目。垃圾收集器将任何有效的内存元数据检查点到交换区,并且不从SSD读取任何日志。标记每个检查点条目的元数据头中的元数据类型,以将它们与正常的元数据更新区分开来。检查点完成后,将旧的元数据区域重置为交换区域。
元数据标头:RAIZN中的每个持久化元数据日志都包含一个元数据头,其中包括元数据类型,元数据描述的LBA范围,包含上述LBA的逻辑区域的生成计数器。
生成计数器:它是RAIZN在卷生命周期内唯一标识给定LBA内容的方法,每次重置(逻辑)区域时,其生成计数器增加1。当与LBA配对时,这个单调递增的计数器用于跟踪元数据日志的有效性。此属性是RAIZN元数据管理的关键:如果元数据头包含过时的生成计数器,则由于逻辑区域被重置,与该头关联的元数据将无效。
元数据垃圾收集:RAIZN定期对元数据进行GC。RAIZN垃圾收集器使用交换区在不中断操作的情况下促进垃圾收集。RAIZN首先指定一个交换区来替换完整的元数据区,并立即在其中写入任何新的日志条目。垃圾收集器将任何有效的内存元数据检查点到交换区,并且不从SSD读取任何日志。标记每个检查点条目的元数据头中的元数据类型,以将它们与正常的元数据更新区分开来。检查点完成后,将旧的元数据区域重置为交换区域。
解决的问题
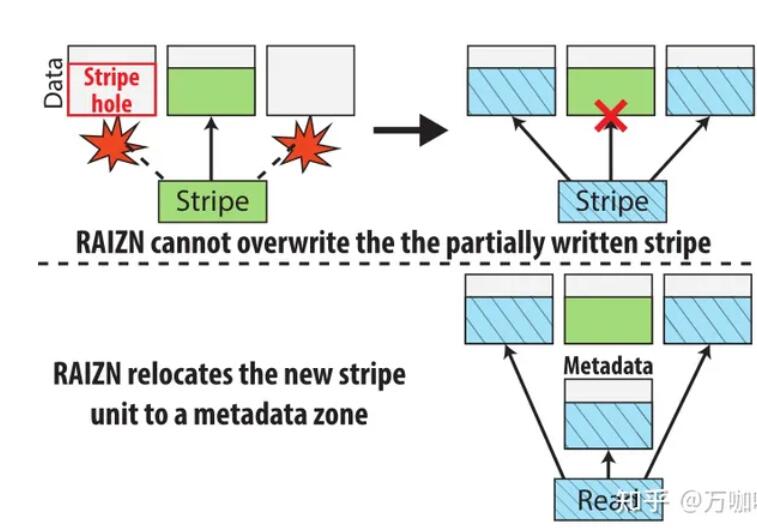
①奇偶校验更新 无论条带对齐如何,所有数据都会立即写入相应的设备,但在写入整个条带之前,相应的奇偶校验是未知的。此问题的一个解决方案是使用单独的随机可写存储设备(例如,持久性存储器、ZNS SSD上的常规命名空间)来缓冲奇偶校验更新或条带写入。RAIZN通过首先将写入的数据缓存在条带缓冲区中,然后将部分奇偶校验持久化到部分奇偶校验元数据区来处理部分写入的条带。一旦填充了条带缓冲区,就会计算完整条带奇偶校验,然后将条带缓冲用于下一个部分条带,逻辑区域通常具有多个活动条带缓冲区。 ②stripe写和区域重置原子性 Write hole:应用程序向存储系统写入数据时,数据会被写入一个或多个块中。由于存储系统的写入操作通常是异步的,也就是说,应用程序认为数据已经被写入了,但是实际上存储系统还没有完成所有的写入操作。如果在写入操作未完成时,存储系统出现故障,例如断电或系统崩溃,那么这些未完成的写入操作所涉及的块数据将会出现不一致性。了解决这个问题,存储系统通常使用一些技术来确保数据的一致性,例如使用日志(Journaling)来记录所有的写入操作,或者使用写时复制(Copy-On-Write)等技术来保证数据的完整性。 Torn writes:当应用程序向存储系统写入数据时,数据可能会跨越多个数据块,如果在写操作未完成时,存储系统出现故障,例如断电或系统崩溃,那么这些未完成的写入操作所涉及的块数据将会出现不一致性。当应用程序向存储系统写入数据时,数据可能会跨越多个数据块,如果在写操作未完成时,存储系统出现故障,例如断电或系统崩溃,那么这些未完成的写入操作所涉及的块数据将会出现不一致性。 在保留所有的条带单元之前,系统断电就会导致数据不足,无法修复丢失的条带单元。在正常的RAID中,单个持久化条带单元的存在不是问题,因为在同一LBA上的额外写入可以简单地覆盖相应的PBA;ZNS不允许重写,因此RAIZN必须将新数据放置在其他位置。 stripe写原子性:RAIZN将新的条带单元重新定位到受影响设备上的元数据区域,生成重新定位的条带单位元数据条目。此条带单元的修改LBA到PBA映射存储在哈希映射中,如果正在读取的逻辑区域被标记为包含重新定位的条带单元,则在读取时检查哈希映射。 图展示了使用RAIZN时一个分条中的一个分条单元子集在掉电之前被持久化,但是这个子集不足以在重启后恢复分条,即Torn writes。传统RAID允许用户覆盖这个条带而不会出现问题,但是如果不重置整个区域,则无法覆盖已经持久化的ZNS条带单元。因此,传统的RAID地址到设备地址的算术映射不能支持ZNS,并且需要额外的间接层。在设计RAIZN以处理此类边缘情况而不损害性能时,这一间接层提出了一个挑战。
 区域重置原子性:当逻辑区域中的物理区域的子集在断电之前未重置时,会发生部分区域重置(即区域重置还没结束,设备就断电了,导致只有一部分区域被重置)。在许多情况下,这可以在初始化期间通过检测逻辑地址空间中的漏洞来检测和处理。但如果区域中存在第一条带单元,则无法区分部分条带写入和部分区域重置。为了解决这种模糊性,我们使用预写日志记录进行区域重置,将重置区域的意图记录到逻辑区域中持有第一条带单元的物理设备和持有区域中第一条带奇偶校验的物理设备。这会增加区域重置的延迟,但因为典型的工作负载在重置区域后不会立即写入区域,所以延迟问题不大。
③写入持久性
如果某个给定LBA上的数据未被持久化,但同一区域中前面的LBA已经被持久化,那么这个区域的逻辑地址空间的部分就会变得不可读,因为无法确保这部分数据的完整性和可靠性
在RAIZN中引入了一个额外的约束:给定LBA处的数据不应可读,除非同一区域中的所有先前LBA也可读。
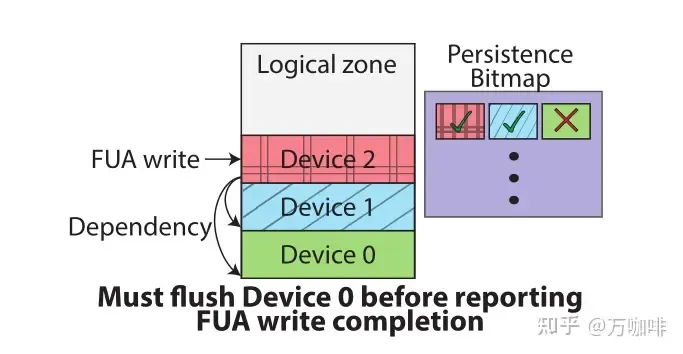
在ZNS中,写入不能跨越多个区域。这需要在FUA写入上设置REQ_PREFLUSH标志,并向同一逻辑区域中包含非持久化条带单元的每个设备提交刷新子IO。为了跟踪逻辑区域中数据的持久性,RAIZN在内存中维护一个称为持久性的位图,以跟踪哪些LBA已被持久化。持久性位图每个条带单元有一位,每次刷新、预刷新或FUA写入完成时,都会为每个活动逻辑区域更新持久性位图,将持久性位图中的相应位设置为写入指针。
区域重置原子性:当逻辑区域中的物理区域的子集在断电之前未重置时,会发生部分区域重置(即区域重置还没结束,设备就断电了,导致只有一部分区域被重置)。在许多情况下,这可以在初始化期间通过检测逻辑地址空间中的漏洞来检测和处理。但如果区域中存在第一条带单元,则无法区分部分条带写入和部分区域重置。为了解决这种模糊性,我们使用预写日志记录进行区域重置,将重置区域的意图记录到逻辑区域中持有第一条带单元的物理设备和持有区域中第一条带奇偶校验的物理设备。这会增加区域重置的延迟,但因为典型的工作负载在重置区域后不会立即写入区域,所以延迟问题不大。
③写入持久性
如果某个给定LBA上的数据未被持久化,但同一区域中前面的LBA已经被持久化,那么这个区域的逻辑地址空间的部分就会变得不可读,因为无法确保这部分数据的完整性和可靠性
在RAIZN中引入了一个额外的约束:给定LBA处的数据不应可读,除非同一区域中的所有先前LBA也可读。
在ZNS中,写入不能跨越多个区域。这需要在FUA写入上设置REQ_PREFLUSH标志,并向同一逻辑区域中包含非持久化条带单元的每个设备提交刷新子IO。为了跟踪逻辑区域中数据的持久性,RAIZN在内存中维护一个称为持久性的位图,以跟踪哪些LBA已被持久化。持久性位图每个条带单元有一位,每次刷新、预刷新或FUA写入完成时,都会为每个活动逻辑区域更新持久性位图,将持久性位图中的相应位设置为写入指针。
测试评估
①64KB条带单元在RAIZN中表现最佳。 ②RAIZN实现了与mdraid类似的吞吐量和延迟,但在粒度较小块下(4–64 KiB)读写方面稍差。 ③mdraid可能会因设备垃圾收集而导致无法预测的严重性能下降,而RAIZN不受影响,因为ZNS SSD不执行设备垃圾收集。 ④RAIZN使用ZNS接口在更换故障设备后最大限度地缩短重建时间。 ⑤RAIZN实现了与RocksDB和MySQL基准上的mdraid类似的稳态吞吐量和尾部延迟。