思考
这篇论文主要解决了什么问题,实现了什么东西?
主要讲述如何在ZNS SSDs 上有效的部署RAID。
ZNS SSD可以通过使用Zone Append命令来利用Zone内部并行性,以达到提升写入性能的目的;但是在ZNS RAID阵列中,使用Zone Append命令并不能达到很好的性能,因为Zone Append将地址管理卸载到了ZNS SSD,并要求主机专门管理跨多个驱动器的RAID条带。
Zone Append在ZNS RAID中的问题具体来说为以下两点:
(1)主机不仅无法直接指定在区域内写入的块地址,而且无法控制并发Zone Append命令的写入顺序;
(2)在Zone Append的情况下,RAID控制器需要维护专用的地址映射信息来指定每个条带的块位置,这无可避免地会导致条带管理的性能损失。
为了解决上述问题,本文实现了一个专为ZNS SSD设计的高性能软件RAID层,通过控制使用Zone Append 来实现高写入并行性和轻量级条带管理。
技术关键是什么?
ZapRAID的核心思想是基于组的数据布局,跨多个条带组进行粗粒度排序,以便可以在每个组的基础上使用小型元数据进行条带管理。
有哪些内容对我有用?
(1) 对于Zone Append和Zone Write命令的分析与比较 –> 有助于我后续工作。
(2) 新的数据结构设计,文中将多个条带划分到一个组里,进行粗粒度管理 –> 细粒度带来开销大就考虑粗粒度。
(3) 在使用Zone Append的同时,穿插了Zone Write命令的使用 –> Zone Write和 Zone Append可以结合使用来达到更高的性能。
分析Zone Append的优势(Zone Append vs Zone Write)
Zone Append命令能够利用 intra-zone parallesim,并且在请求大小为 4 KiB时的吞吐量高于 Zone Write
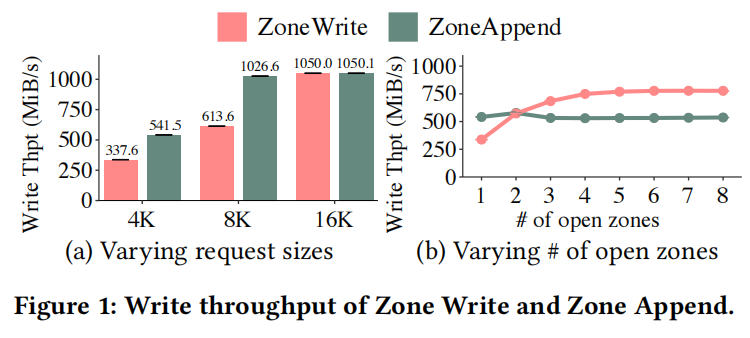
a. Zone Write:先命名后写入,即先为数据分配LBA地址,然后下发数据写请求到存储设备;每个分区的写请求队列深度为1,一个在任何时候只能有一个未完成的区域写入,并且写吞吐量不能通过并发写请求进一步增加 –> 限制了 intra-zone parrallesim
b. Zone Append:先追加写后命名,主机能够同时提交多个append命令到SSD,每个命令指定目标分区地址;SSD能够在目标分区上以任意顺序并发执行append命令,待写入完成数据页才被分配LBA地址 –> 能够利用 intra-zone parallesim
c. Zone Write 命令执行吞吐量会随 open zones 数量增加 ,而 Zone Append 命令其硬件实现计算量较大,限制其吞吐量增加。 –> 本文仅考虑open zones=1。
d. 4 KiB的写入请求大小通常在存储工作负载中,如在生产服务器和云块存储中,因此区域追加可以有利于这类应用程序。 –> 4KiB下,Zone Append性能优于Zone Write,所以选择以Zone Append为主。
分析Log-Structured RAID的特性
- 使用Log-RAID的原因:因为SSD采用错位更新,小写会触发频繁的GC,降低性能。而Log-RAID 通过下发顺序的 host-level writes 来删除 small writes,将日志化结构应用到SSD RAID。
- Log-RAID的特性:Log-RAID 管理仅支持追加写(append)的 segments 中的 stripes ,每个segment 包含多个 stripes。log-RAID 将新的写入块聚合成新的 stripes,它以 append 的方式将新的 stripe 写到每个 segment 中相同的偏移量的位置,并存储在不同驱动器在进行容错。
ZapRAID 设计
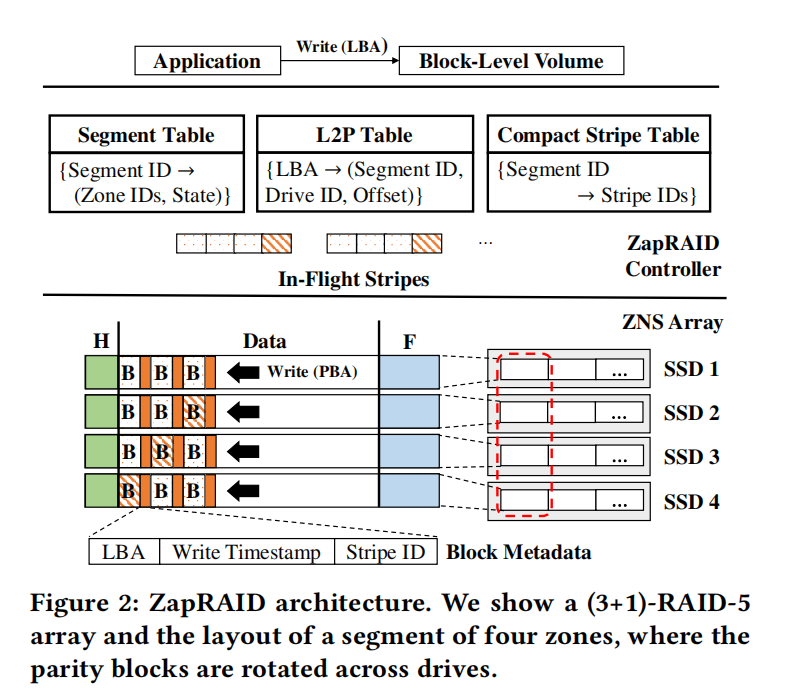
ZapRAID的体系结构如 Figure 2 所示。一些设计介绍如下:
- 每个段对应于𝑘+𝑚驱动器中的𝑘+𝑚区域。它包括跨越𝑘+𝑚驱动器的三个区域:Header Region 和用于保存崩溃恢复的元数据的 Footer Region,以及用于存储数据和奇偶校验块的 Data Region 。Header Region 存储数据段中所有区域的区域ID。Footer Region 保留块元数据,包括Data Region 中每个块的LBA、写入时间戳和条带ID。
- ZapRAID将每个块的块元数据存储在对应的闪存页面的条带外区域中(out-of-band area),以保持持久性。每个数据块都有其LBA、写时间戳和条带ID作为其块元数据。
- ZapRAID为新编写的块保留了一些内存条带。每个未完成的条带都保存在内存中,直到其所有𝑘数据块和𝑚奇偶校验块形成并持久存化。
- ZapRAID维护三个内存中的索引结构:Segment Table 、L2P Table、Compact Stripe Table。
最关键的设计在于基于组的数据布局(Group-Based Data Layout),如 Figure 3 所示。
具体实现细节:ZapRAID采用基于组的数据布局,以粗粒度顺序组织条带,以实现低条带管理开销。它将一个段中由𝐺表示的固定数量的连续条带划分为条带组,其中𝐺是一个可配置的参数。对于每个条带组,它首先对同一条带组中除最后一个条带发出区域附加,这样每个条带的所有块都在同一条带组中,但可能位于条带组中的不同偏移量中。然后,它为最后一条条带发出区域写区。因此,每个区域写都可以作为相邻条带组之间的显式排序屏障。每个条带组在所有区域中都具有相同的偏移范围,因此可以通过静态映射来识别其块的偏移范围。最重要的是,ZapRAID只需要跟踪每个条带组中的少量条带,因此它可以减少对元数据的使用位,从而显著节省内存。
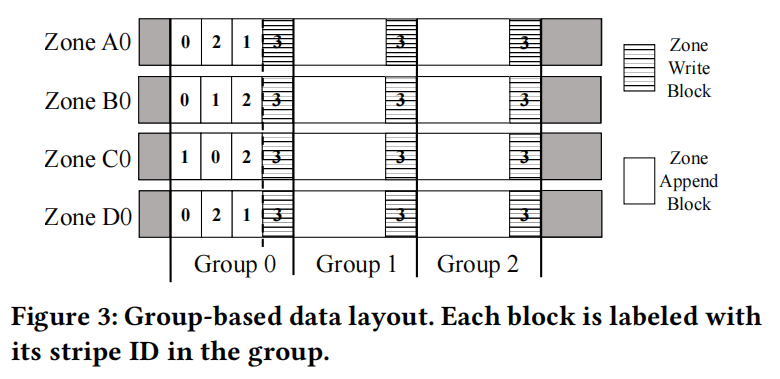
关于G(group size)的分析:G的选择决定了通过区域附加程序实现的区域内并行性程度和条带管理开销之间的权衡。更大的𝐺允许通过区域附加程序发布更多的条带,但它也增加了条带管理开销。
Evaluation
实验结果见 Figure 4~6。
实验结论:ZapRAID 比单独使用 Zone Write 提高了写吞吐量,同时保持了高效的降级读取和崩溃恢复。
